*************************** APPLICATION FAILED TO START ***************************
Description:
The dependencies of some of the beans in the application context form a cycle:
┌─────┐ | componentA ↑ ↓ | componentB └─────┘
Action:
Relying upon circular references is discouraged and they are prohibited by default. Update your application to remove the dependency cycle between beans. As a last resort, it may be possible to break the cycle automatically by setting spring.main.allow-circular-references to true.
Ron 认为,作为新手入门的第一个程序,这段代码太复杂了。比如 class 声明和强制性的 public 访问修饰符是大型编程结构,它们在封装具有定义良好的外部组件接口的代码单元时很有用,但在这个入门小示例中毫无意义。String [] args 参数用于将代码与外部组件连接起来,但在这段代码里面不会被使用。static 修饰符是 Java 类和对象模型的一部分,但在新手村出现也为时尚早。
作为优化,该提案首先增强了启动 Java 程序的协议灵活性:
允许已启动类的 main 方法具有 public 、 protected 或默认(即包)访问权限。
如果启动的类不包含带 String [] 参数的 static main 方法,但包含不带参数的 static main 方法,则调用该方法。
如果启动的类没有 static main 方法,但有一个非 private 零参数构造函数(即 public 、 protected 或包访问)和一个非 private 实例 main 方法,然后构造该类的一个实例。如果该类有一个带 String [] 参数的实例 main 方法,则调用该方法;否则,不带参数调用实例 main 方法。
如此一来便允许省略 main 方法的 String[] 参数,并允许 main 方法既不是 public 也不是 static 。可以稍微简化 Hello, World! :
@RestController @Slf4j @BusLog(name = "人员管理") @RequestMapping("/person") public class PersonController { @Autowired private IPersonService personService; private Integer maxCount=100;
@PostMapping @NeedEncrypt @BusLog(descrip = "添加单条人员信息") public Person add(@RequestBody Person person) { Person result = this.personService.registe(person); log.info("//增加person执行完成"); return result; } @PostMapping("/batch") @BusLog(descrip = "批量添加人员信息") public String addBatch(@RequestBody List personList){ this.personService.addBatch(personList); return String.valueOf(System.currentTimeMillis()); }
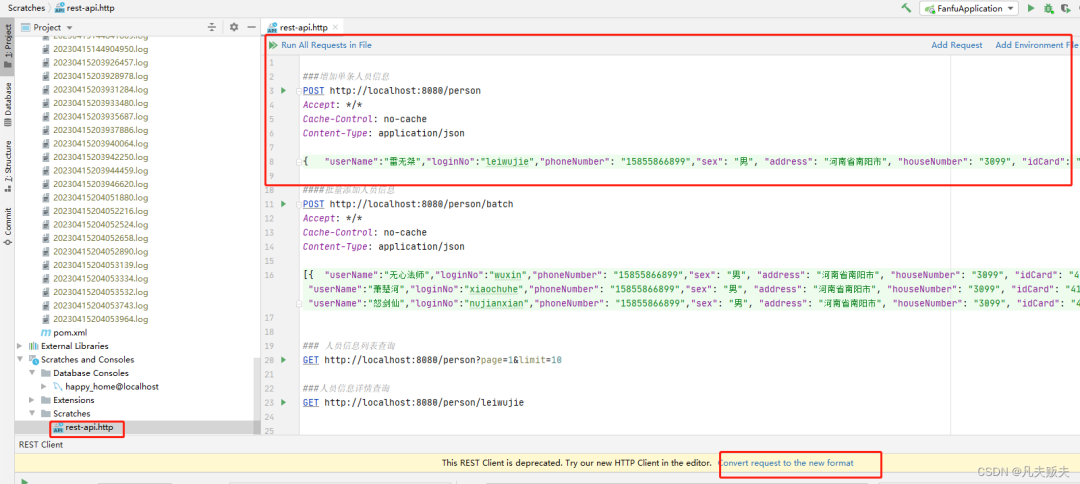
平时后端调试接口,一般都是使用postman,这里给大家安利一款工具,即Intellij IDEA的Test RESTful web service,功能和使用和postman差不多,唯一的好处就是不用在电脑上再额外装个postman,功能入口:工具栏的Tools–>http client–>Test RESTful web
SpringBoot 为我们快速开发提供了很好的架子,使得我们只需要少量配置就能开始我们的开发工作,但是当我们需要打包上传部署时,却是很神伤的一个问题,因为打出来的 Jar 包少则十几兆,多则一百来兆,我们需要上传至公网服务器时,是非常慢的,这就引出了今天的主题,SpringBoot项目Jar包如何瘦身部署
思路
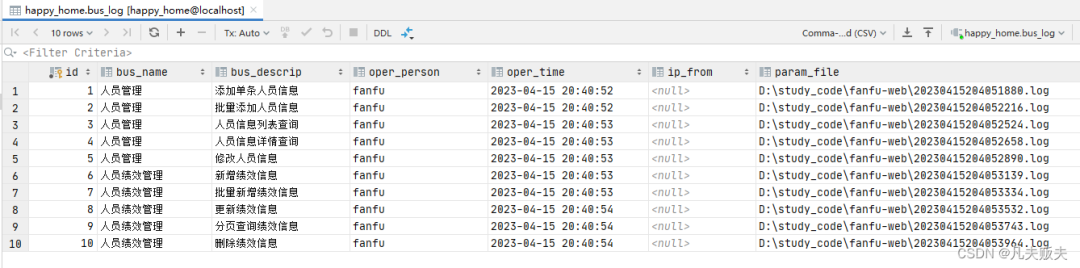
分析 jar,我们可以看出,jar 包里面分为以下三个模块
分为 BOOT-INF,META-INF,org 三个部分,打开 BOOT-INF
可以看到有 classes,lib 两个文件夹,我们编译好的代码是放在 classes 里面的,而我们所依赖的 jar 包都是放在 lib 文件夹下
此版本中新增了对 Spring Authorization Server 项目的支持,同时提供了新的spring-boot-starter-oauth2-authorization-server启动器。有关详细信息,请参阅 Spring Boot 参考文档中的 Authorization Server 部分。
Docker 镜像构建
镜像创建日期和时间
spring-boot:build-image Maven 目标和 bootBuildImage Gradle 任务现在具有 createdDate 配置选项,可用于将生成图像元数据中的 Created 字段的值设置为用户指定的日期或 now 以使用当前日期和时间。有关详细信息,请参阅 Gradle 和 Maven 插件文档。
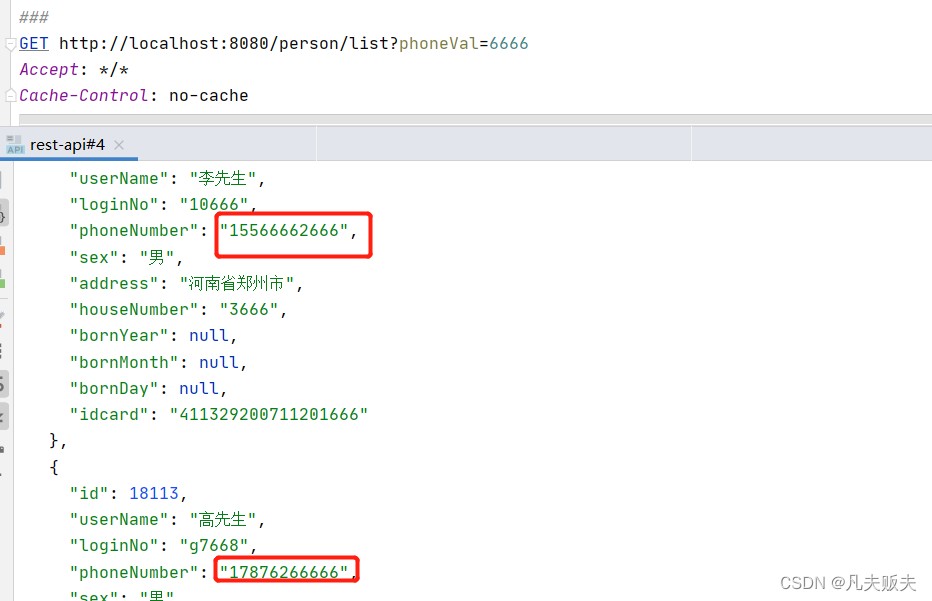
如果用户想要查询真实姓名是包含有“张三”的所有人员信息,可以在页面上输入一个关键字,如“张三”,点击开始查询后,这个参数会传递到后台,后台会执行一条sql,如“select * from sys_person where real_name like ‘%张三%’”,执行结果中包含了所有用户真实姓名包含有“张三”的所有数据记录,如“张三”,“张三丰”等。
如果用户要查询手机号码尾号是“0537”的用户,后台执行类似与姓名模糊查询的sql,”select * from sys_person where phone like '%0537'“,肯定是得不到正确的结果的,因为手机号码字段在数据库中的数据是加密后的结果,而‘0537’是明文。身份证号码、家庭住址等其他敏感字段在模糊查询的时候也都有类似这样的问题,这也是敏感字段模糊查询的痛点,即模糊查询关键字与实际存储的数据不一致。
create table if not exists sys_person_phone_encrypt ( id bigint auto_increment comment '主键' primary key, person_id int not null comment '关联人员信息表主键', phone_key varchar(500) not null comment '手机号码分词密文' ) comment '人员的手机号码分词密文映射表';







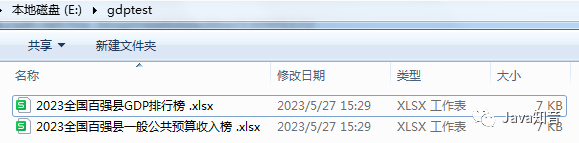
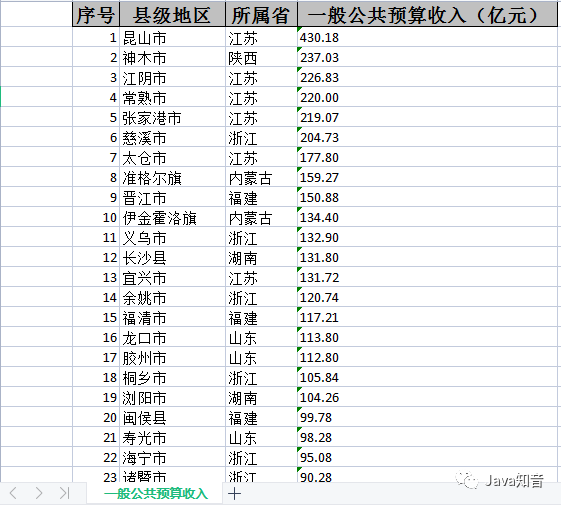
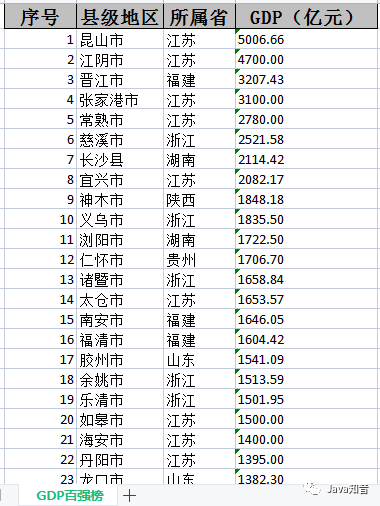







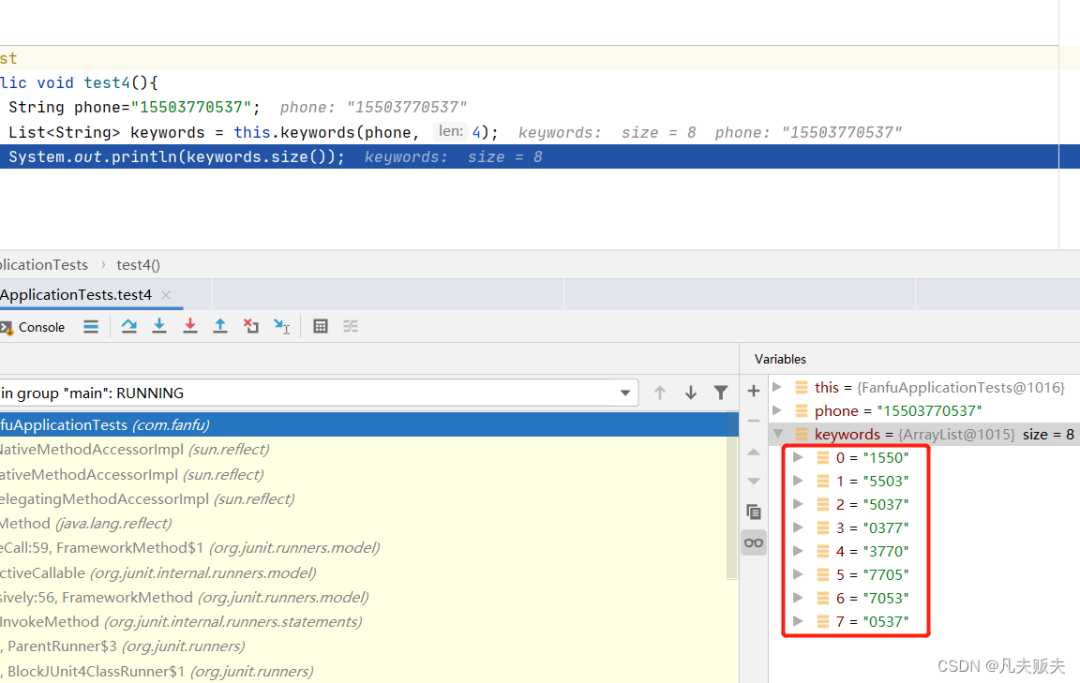 图片一:分组组合加密前
图片一:分组组合加密前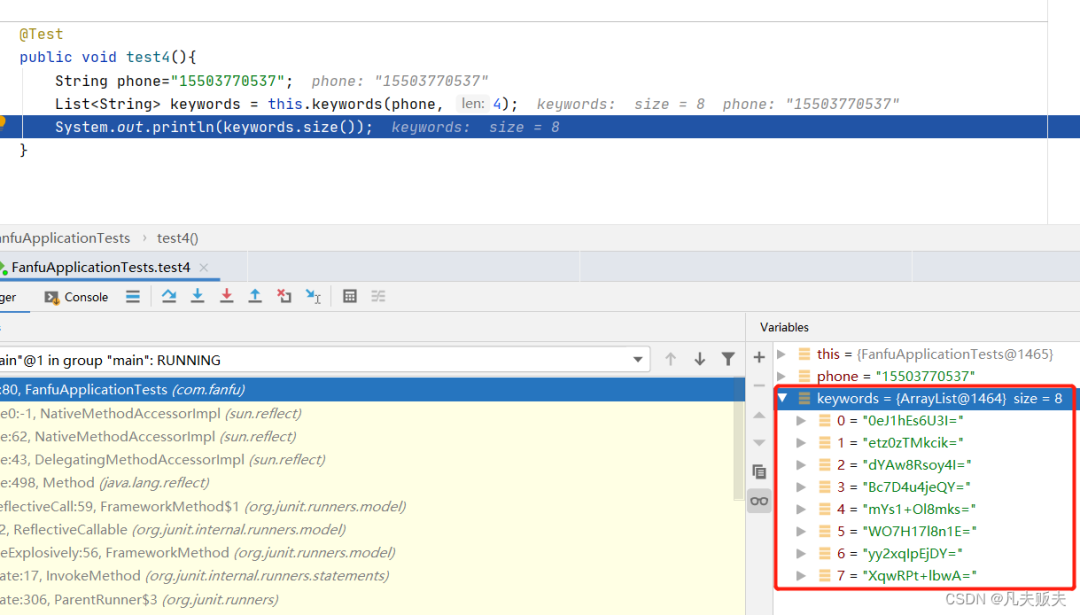 图片二:分组组合加密后
图片二:分组组合加密后