SELECT * FROM `user_operation_log` LIMIT 10000, 10
查询3次时间分别为:
59 ms
49 ms
50 ms
这样看起来速度还行,不过是本地数据库,速度自然快点。
换个角度来测试
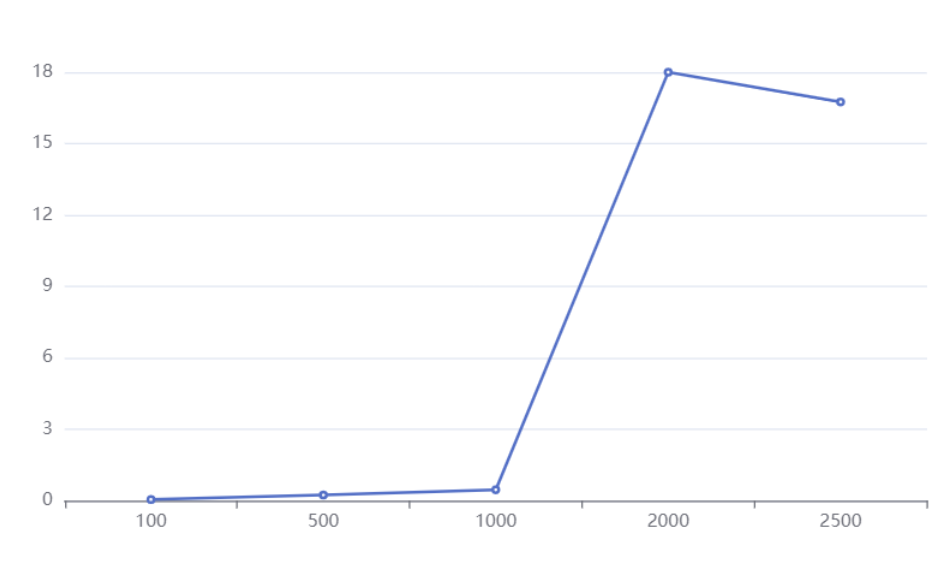
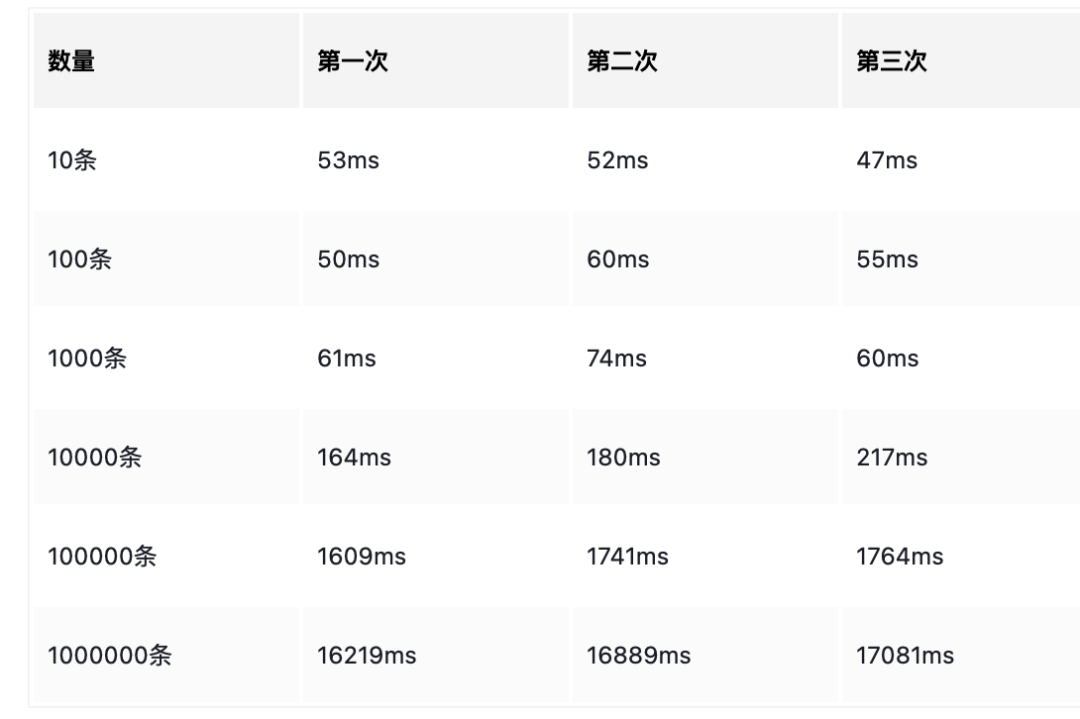
相同偏移量,不同数据量
SELECT * FROM `user_operation_log` LIMIT 10000, 10 SELECT * FROM `user_operation_log` LIMIT 10000, 100 SELECT * FROM `user_operation_log` LIMIT 10000, 1000 SELECT * FROM `user_operation_log` LIMIT 10000, 10000 SELECT * FROM `user_operation_log` LIMIT 10000, 100000 SELECT * FROM `user_operation_log` LIMIT 10000, 1000000
查询时间如下:
图片
从上面结果可以得出结束:数据量越大,花费时间越长
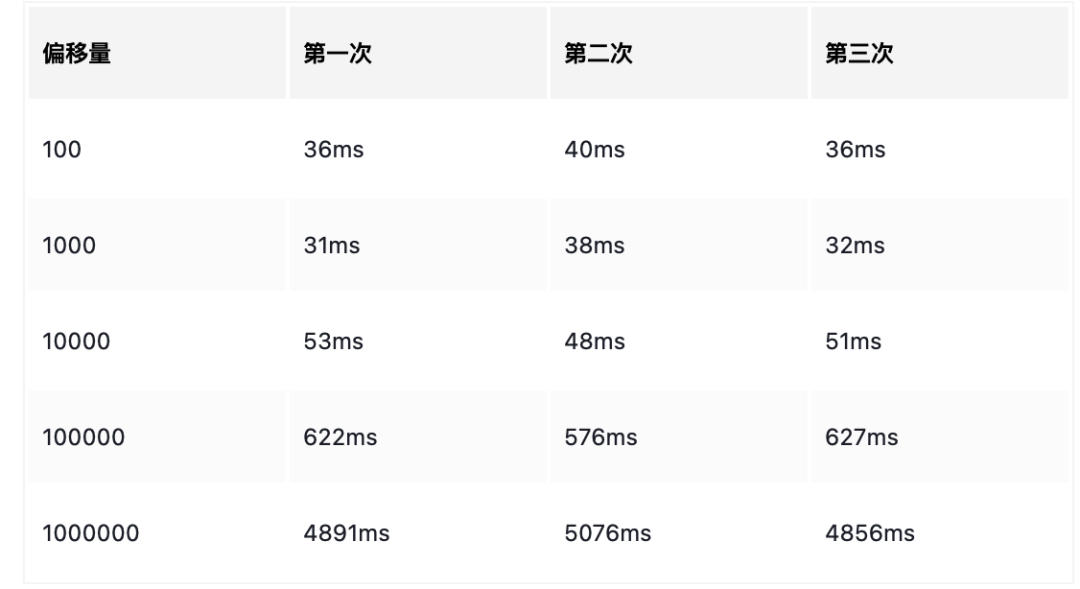
相同数据量,不同偏移量
SELECT * FROM `user_operation_log` LIMIT 100, 100 SELECT * FROM `user_operation_log` LIMIT 1000, 100 SELECT * FROM `user_operation_log` LIMIT 10000, 100 SELECT * FROM `user_operation_log` LIMIT 100000, 100 SELECT * FROM `user_operation_log` LIMIT 1000000, 100
图片
从上面结果可以得出结束:偏移量越大,花费时间越长
SELECT * FROM `user_operation_log` LIMIT 100, 100 SELECT id, attr FROM `user_operation_log` LIMIT 100, 100
如何优化
既然我们经过上面一番的折腾,也得出了结论,针对上面两个问题:偏移大、数据量大,我们分别着手优化
优化偏移量大问题
采用子查询方式
我们可以先定位偏移位置的 id,然后再查询数据
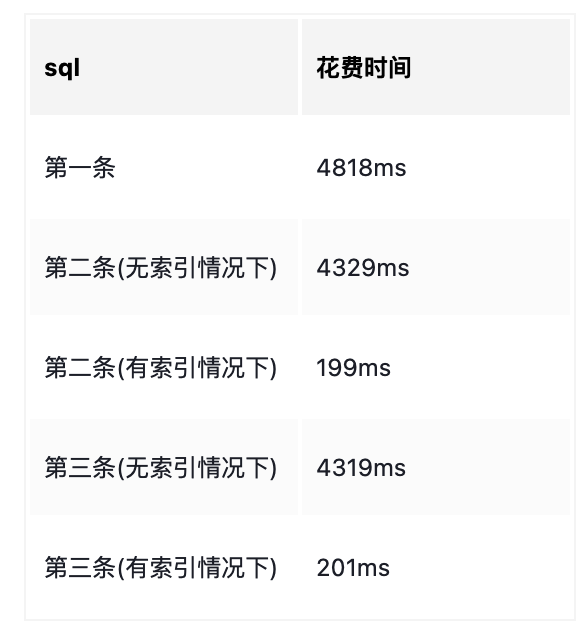
SELECT * FROM `user_operation_log` LIMIT 1000000, 10SELECT id FROM `user_operation_log` LIMIT 1000000, 1SELECT * FROM `user_operation_log` WHERE id >= (SELECT id FROM `user_operation_log` LIMIT 1000000, 1) LIMIT 10
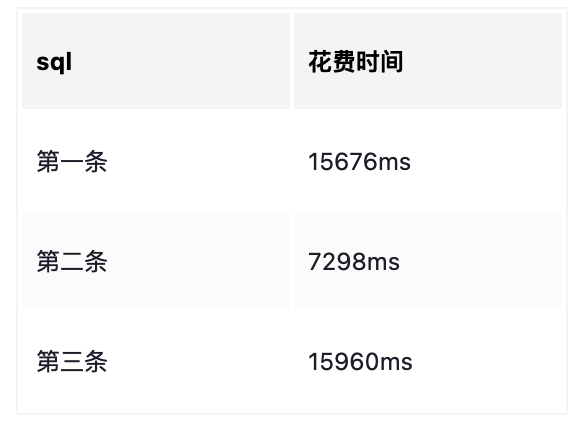
查询结果如下:
从上面结果得出结论:
第一条花费的时间最大,第三条比第一条稍微好点
子查询使用索引速度更快
缺点:只适用于id递增的情况
id非递增的情况可以使用以下写法,但这种缺点是分页查询只能放在子查询里面
注意:某些 mysql 版本不支持在 in 子句中使用 limit,所以采用了多个嵌套select
SELECT * FROM `user_operation_log` WHERE id IN (SELECT t.id FROM (SELECT id FROM `user_operation_log` LIMIT 1000000, 10) AS t)
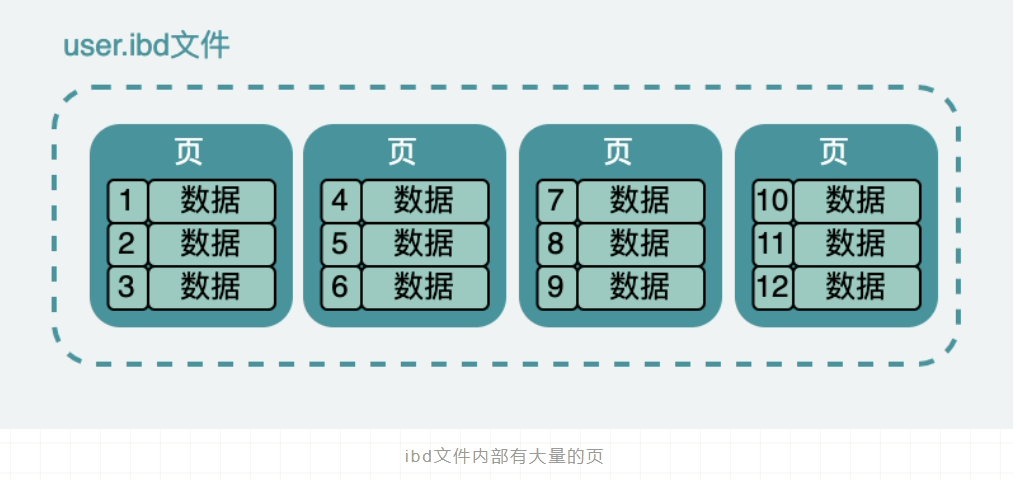
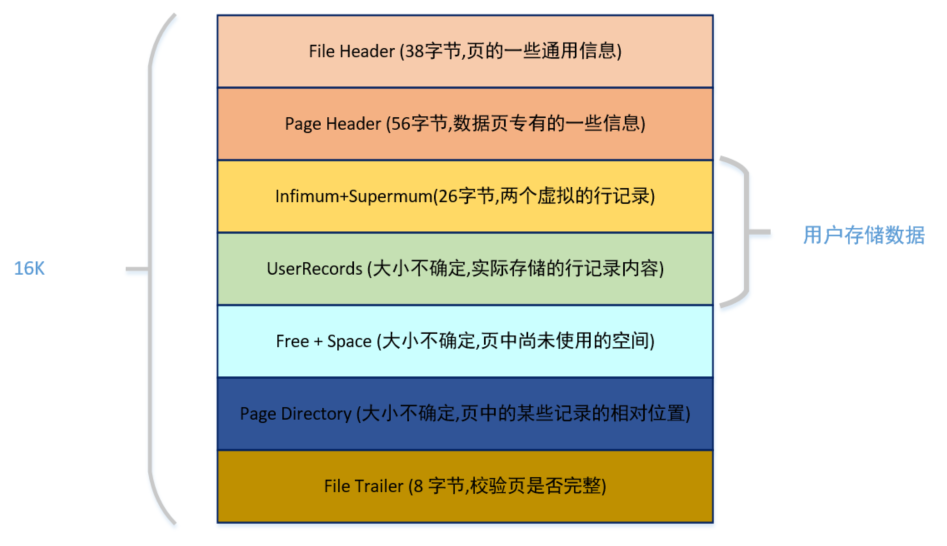
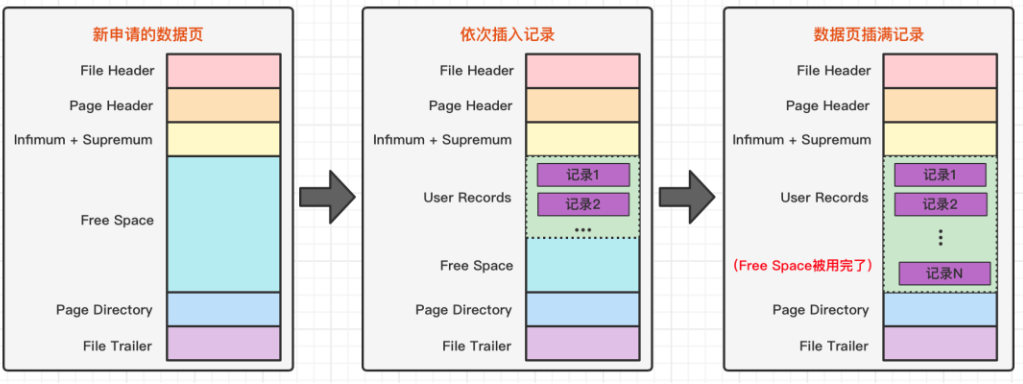
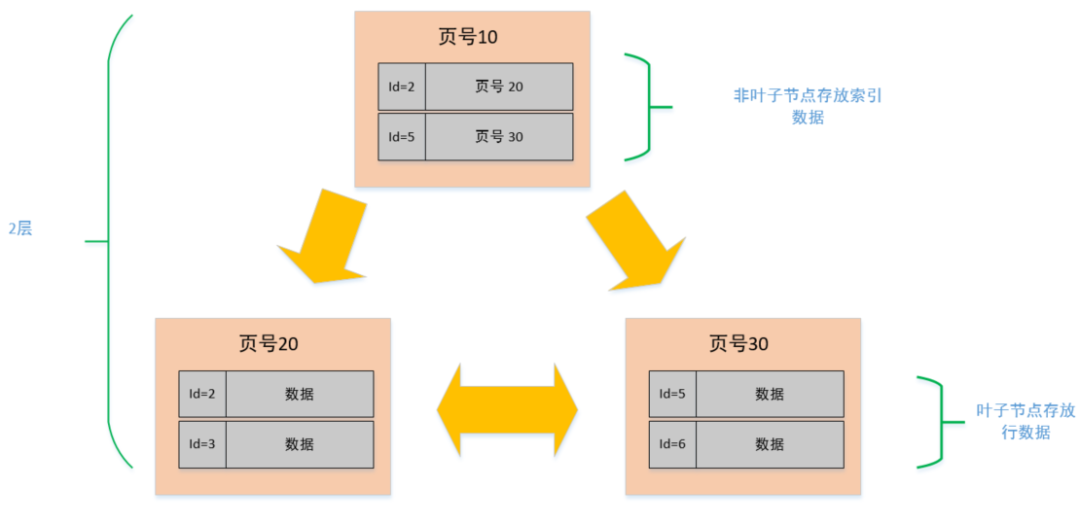
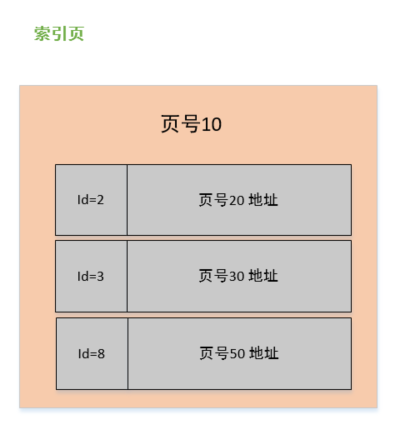
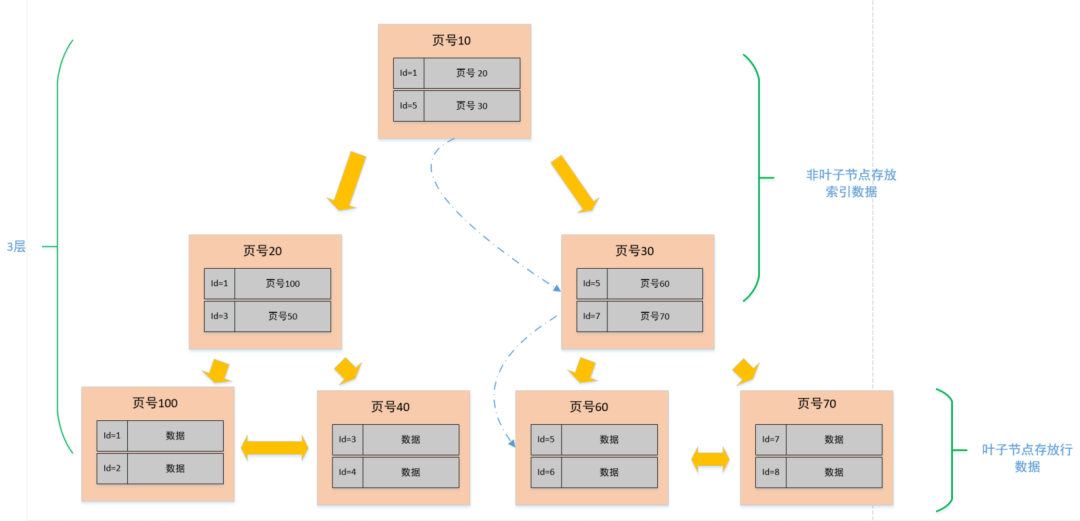
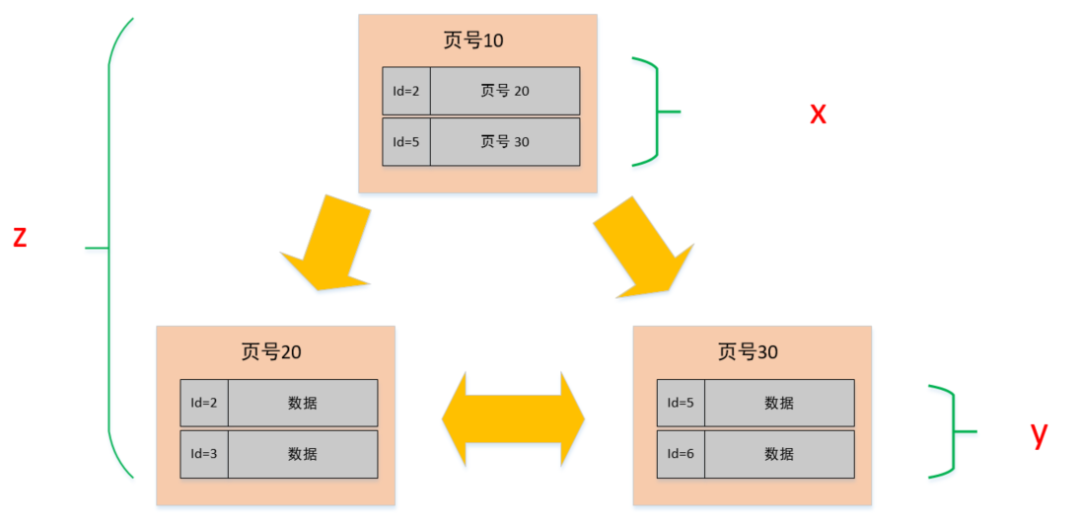
在页的 7 个组成部分中,我们自己存储的记录会按照我们指定的行格式存储到 User Records 部分。
但是在一开始生成页的时候,其实并没有 User Records 这个部分,每当我们插入一条记录,都会从 Free Space 部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到 User Records 部分,当 Free Space 部分的空间全部被 User Records 部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了。这个过程的图示如下。
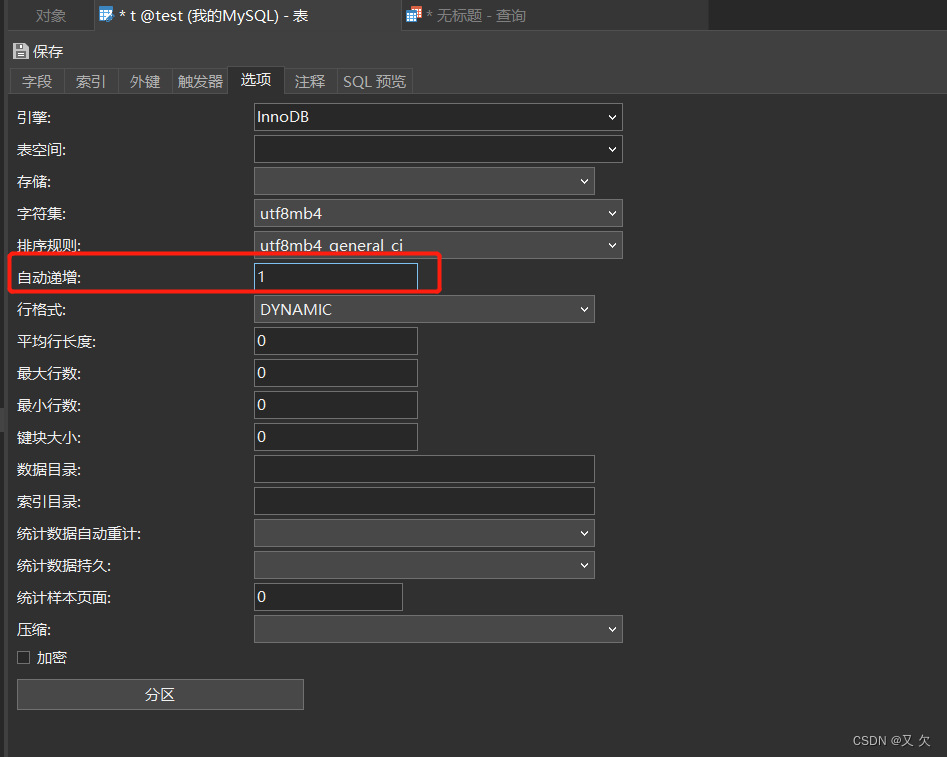
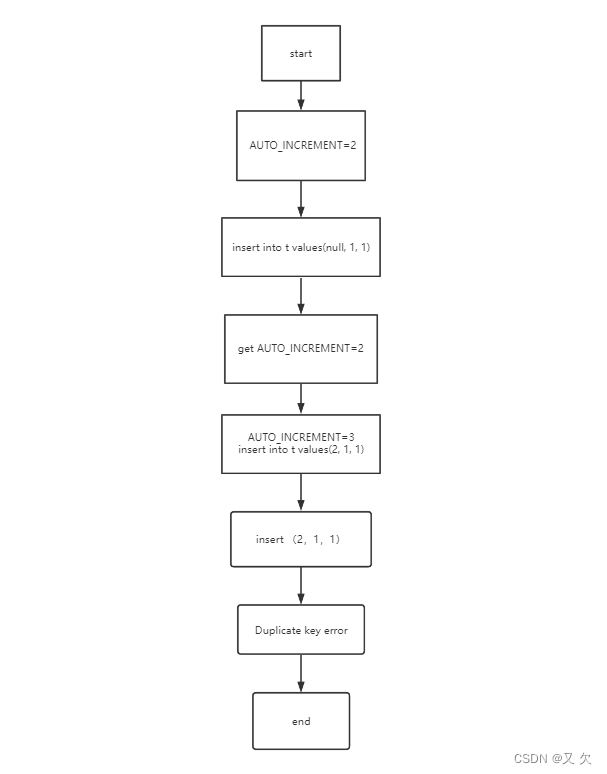
可以看到,这个表的自增值改成 3,是在真正执行插入数据的操作之前。这个语句真正执行的时候,因为碰到唯一键 c 冲突,所以 id=2 这一行并没有插入成功,但也没有将自增值再改回去。所以,在这之后,再插入新的数据行时,拿到的自增 id 就是 3。也就是说,出现了自增主键不连续的情况。
四、自增主键值不连续情况:(事务回滚)
其实事务回滚原理也和上面一样,都是因为异常导致新增失败,但是自增值没有进行回退。
五、自增主键值不连续情况:(批量插入)
批量插入数据的语句,MySQL 有一个批量申请自增 id 的策略:
语句执行过程中,第一次申请自增 id,会分配 1 个;
1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
2 个用完以后,还是这个语句, 第三次申请自增 id,会分配 4 个;
依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
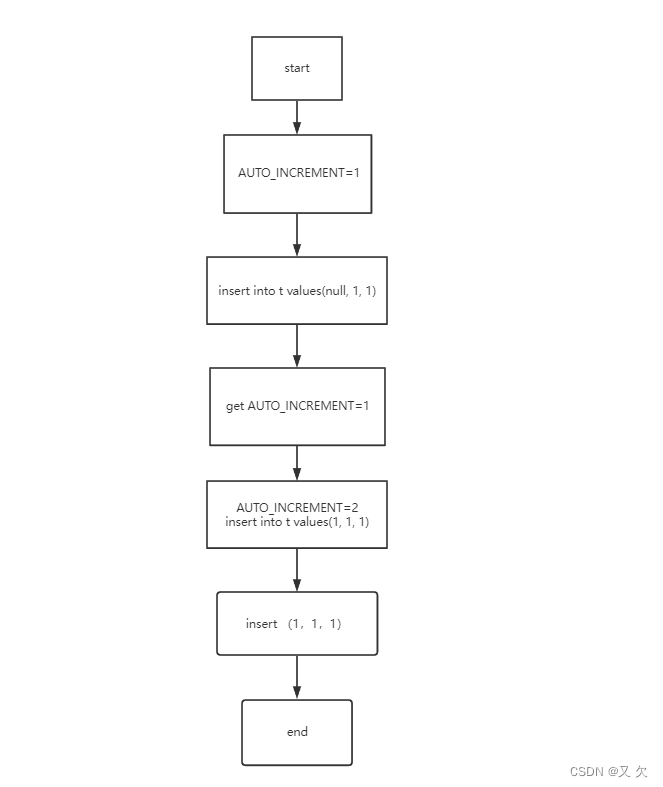
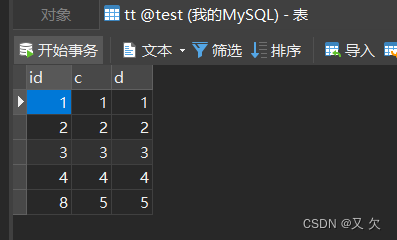
执行以下SQL语句(在表t中先新增了4条数据,在创建表tt把表t数据进行批量新增)
insertinto t values(null, 1,1);
insertinto t values(null, 2,2);
insertinto t values(null, 3,3);
insertinto t values(null, 4,4);
createtable tt like t;
insertinto tt(c,d) select c,d from t;
insertinto tt values(null, 5,5);
 来源:cnblogs.com/liboware/p/12740901.html
来源:cnblogs.com/liboware/p/12740901.html





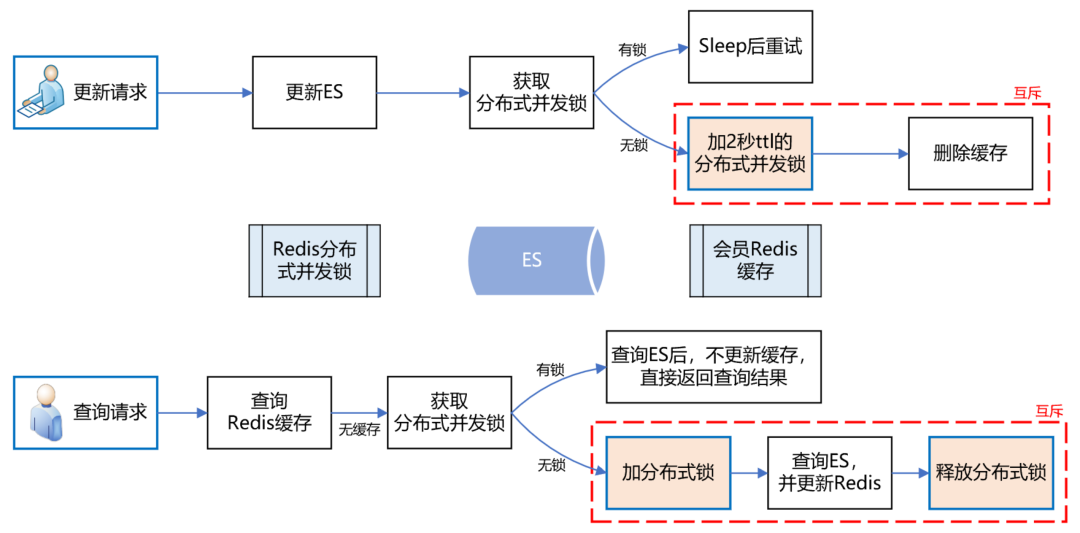
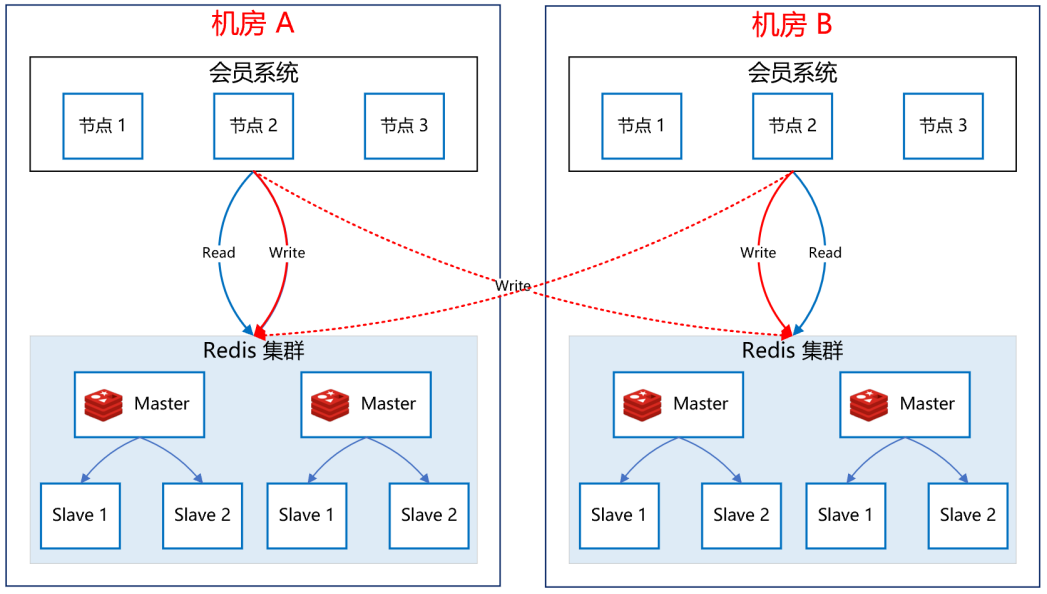
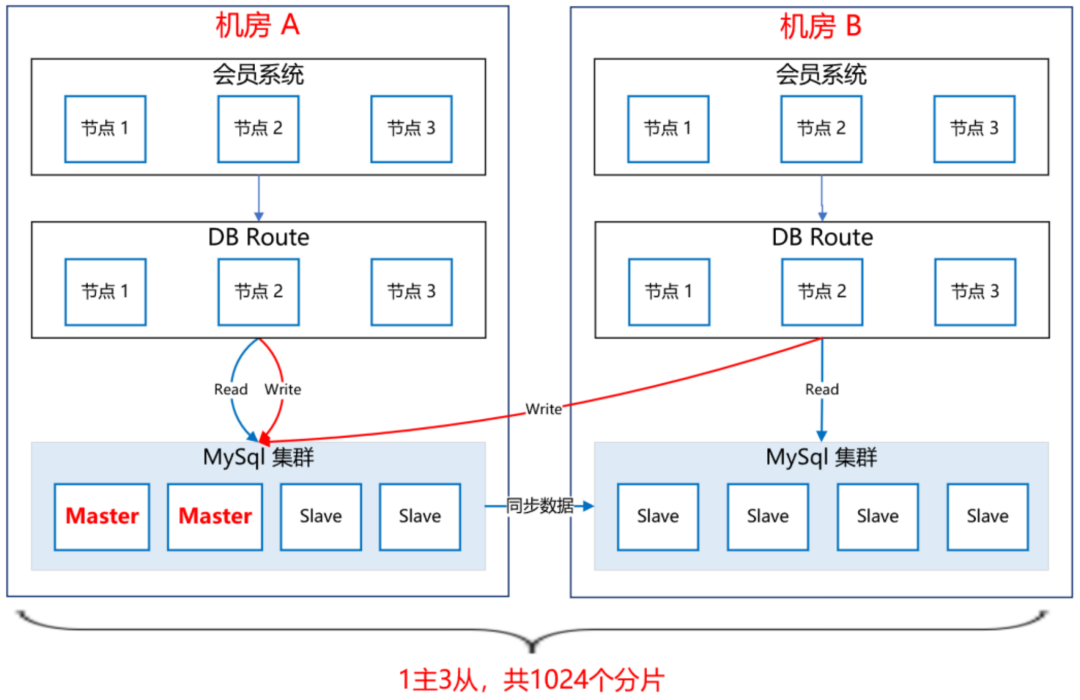
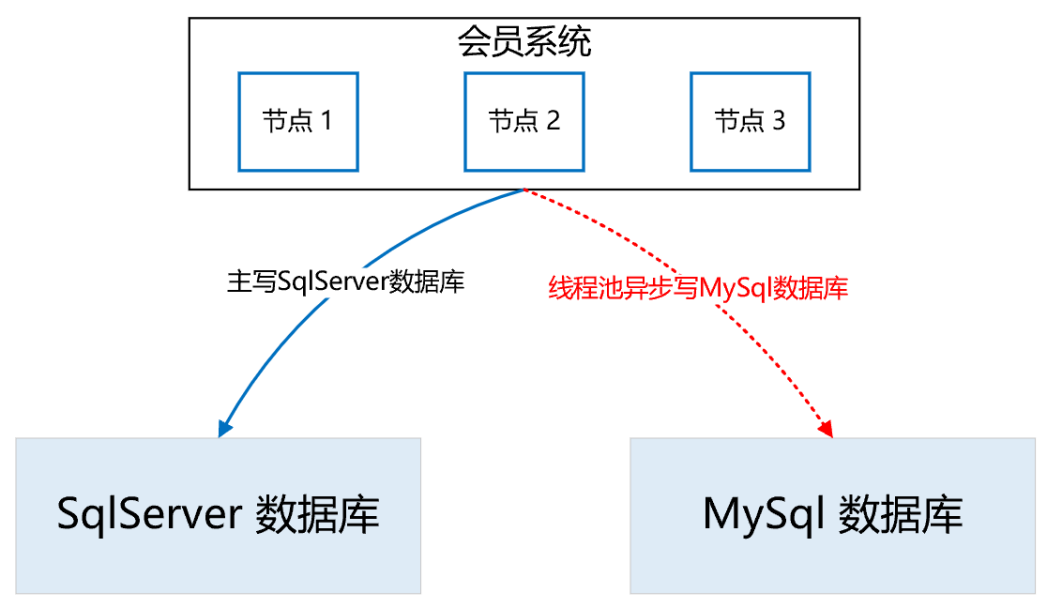
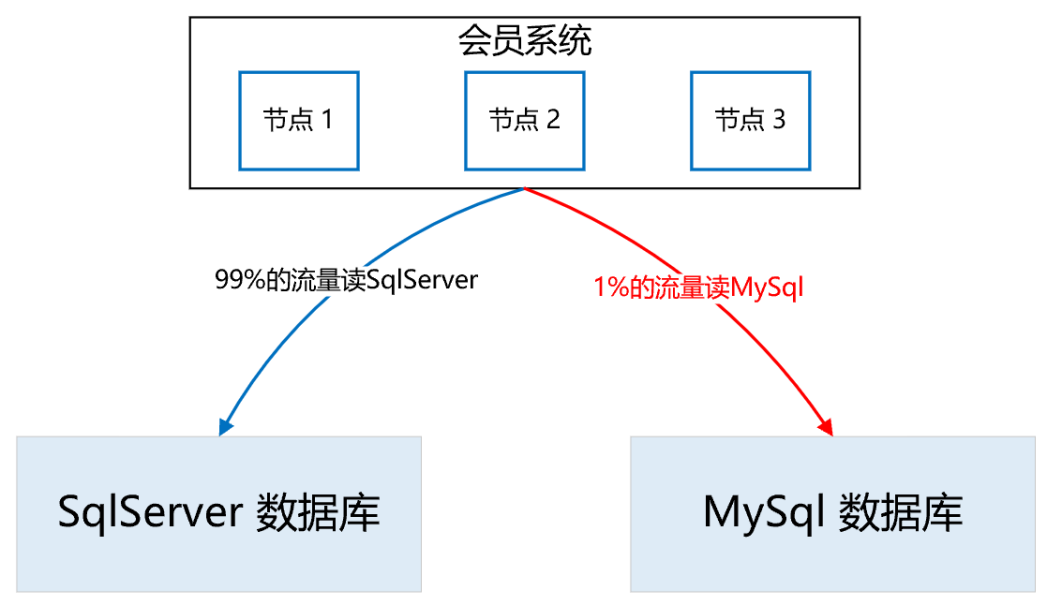

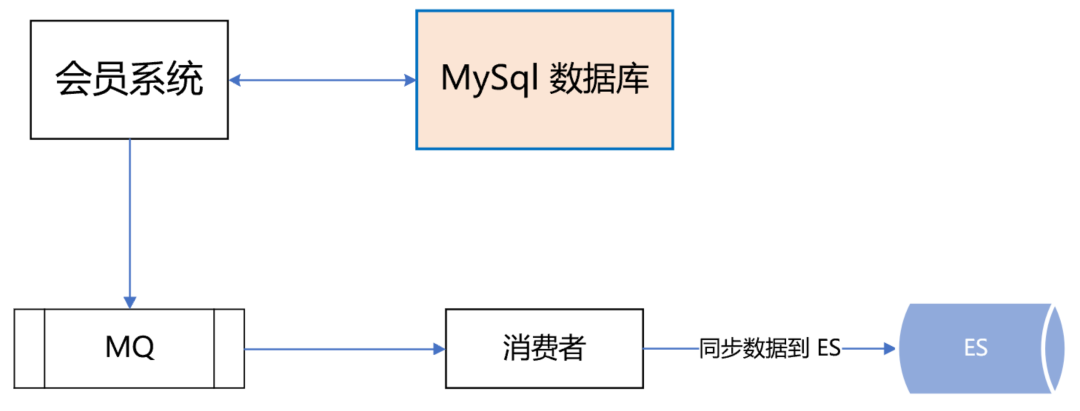
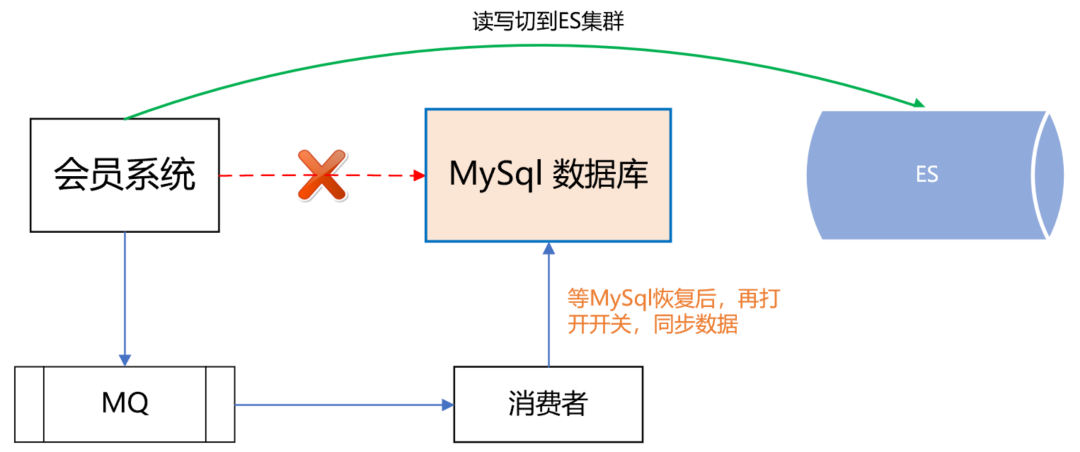



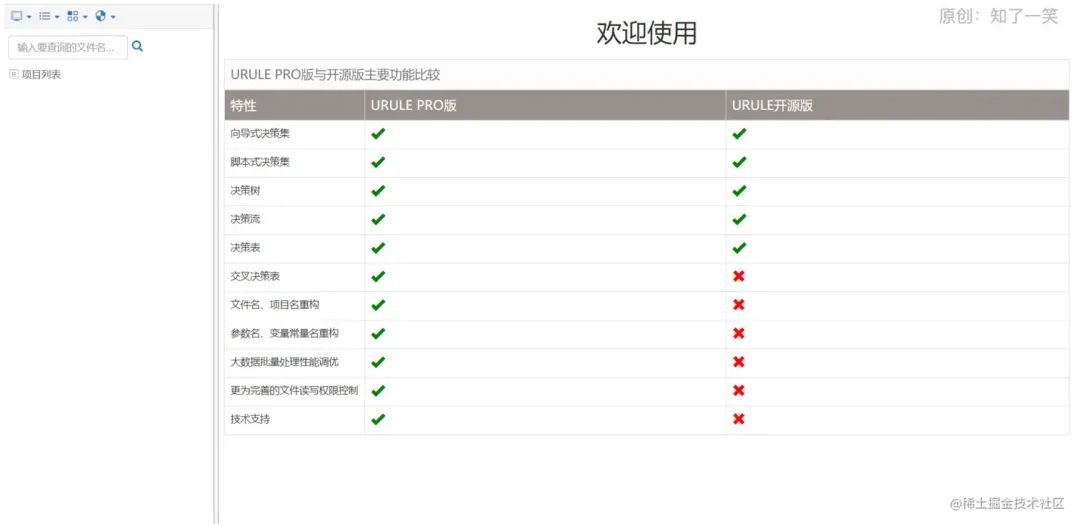
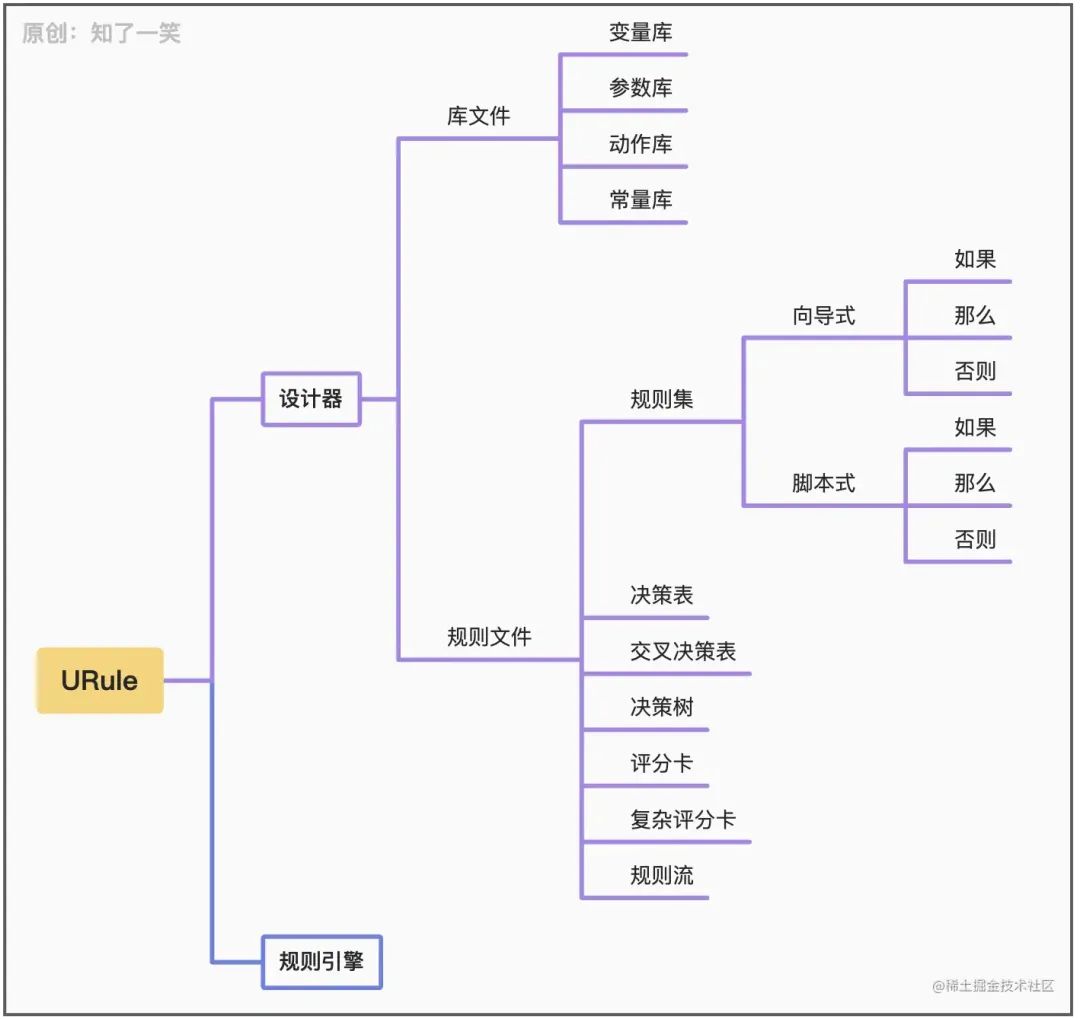
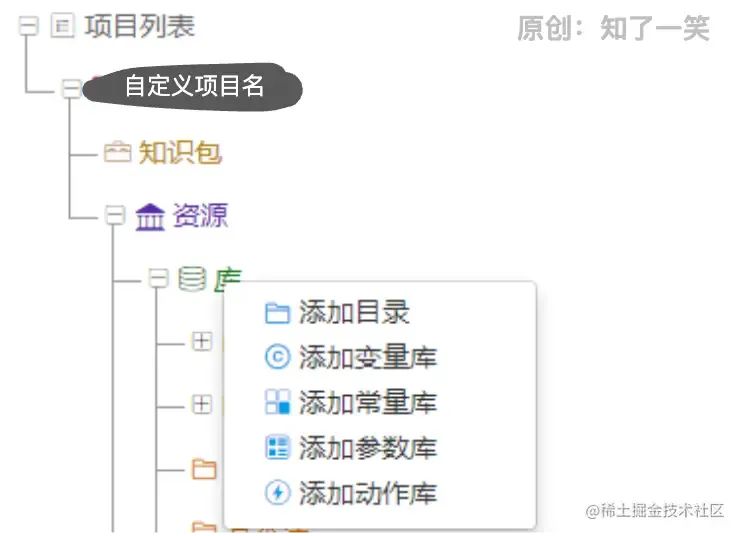
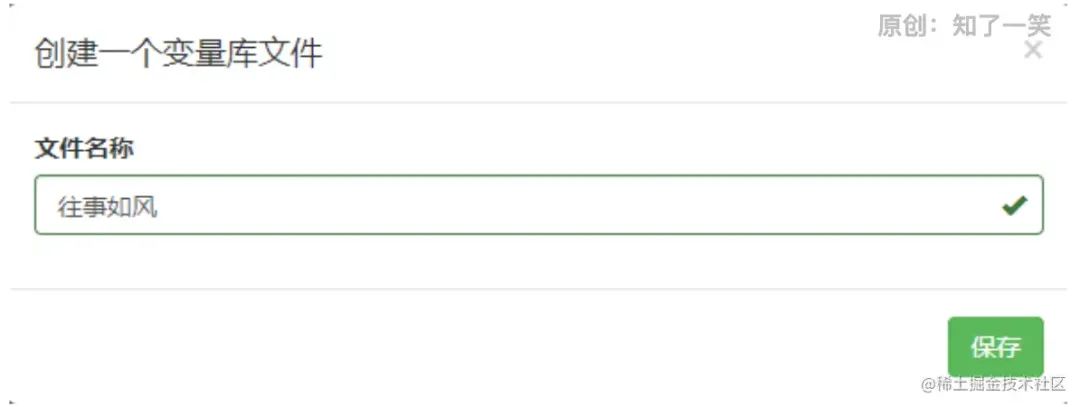

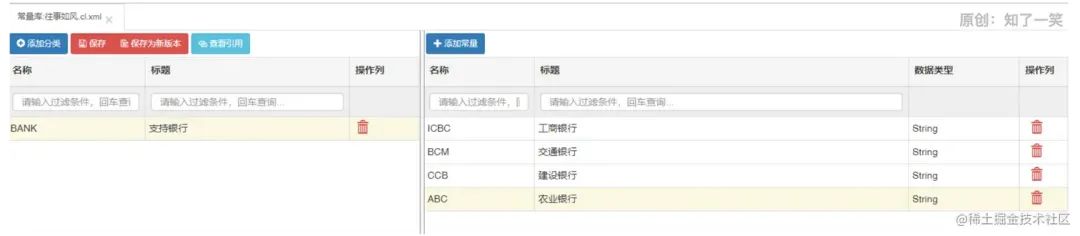


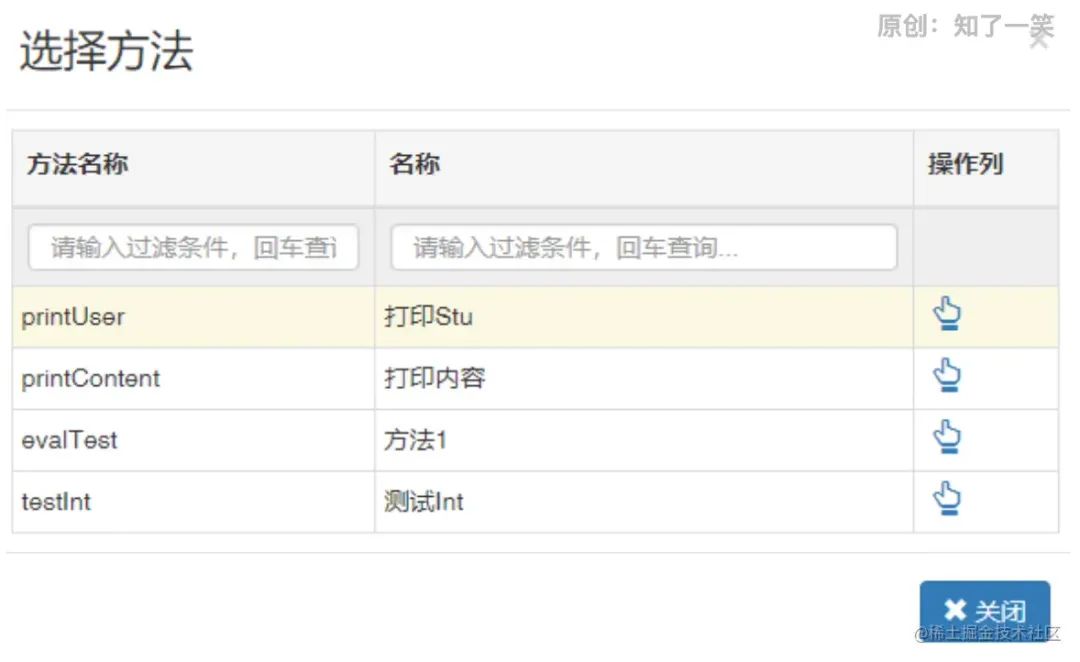

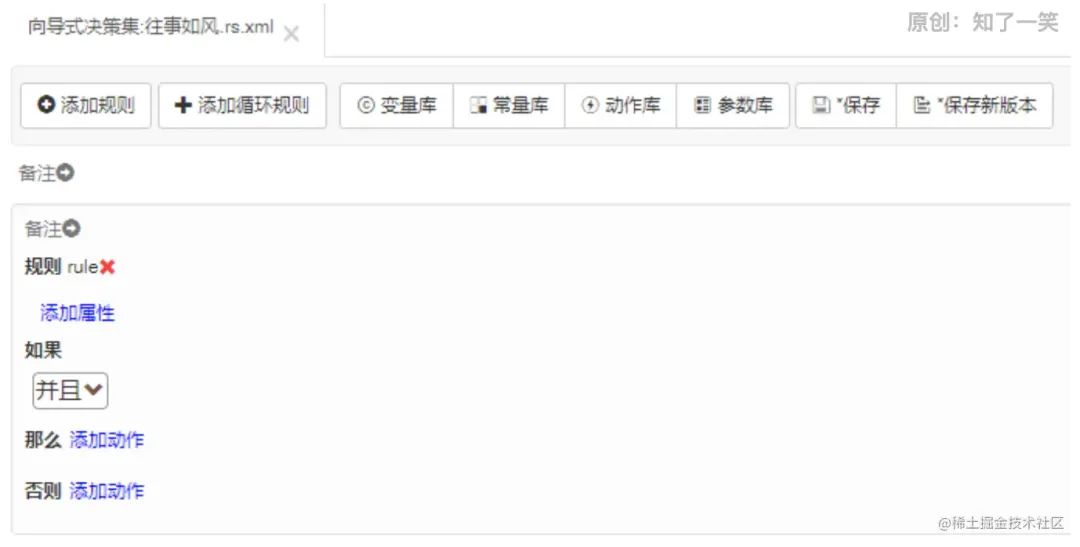
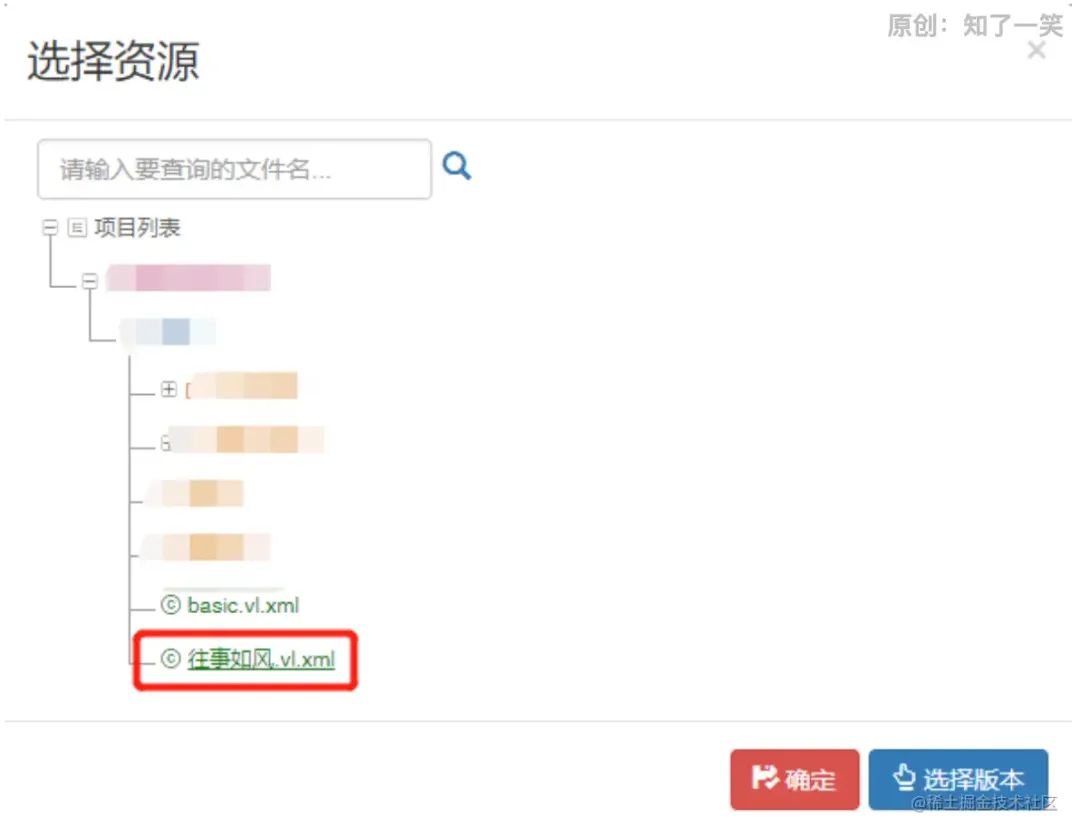

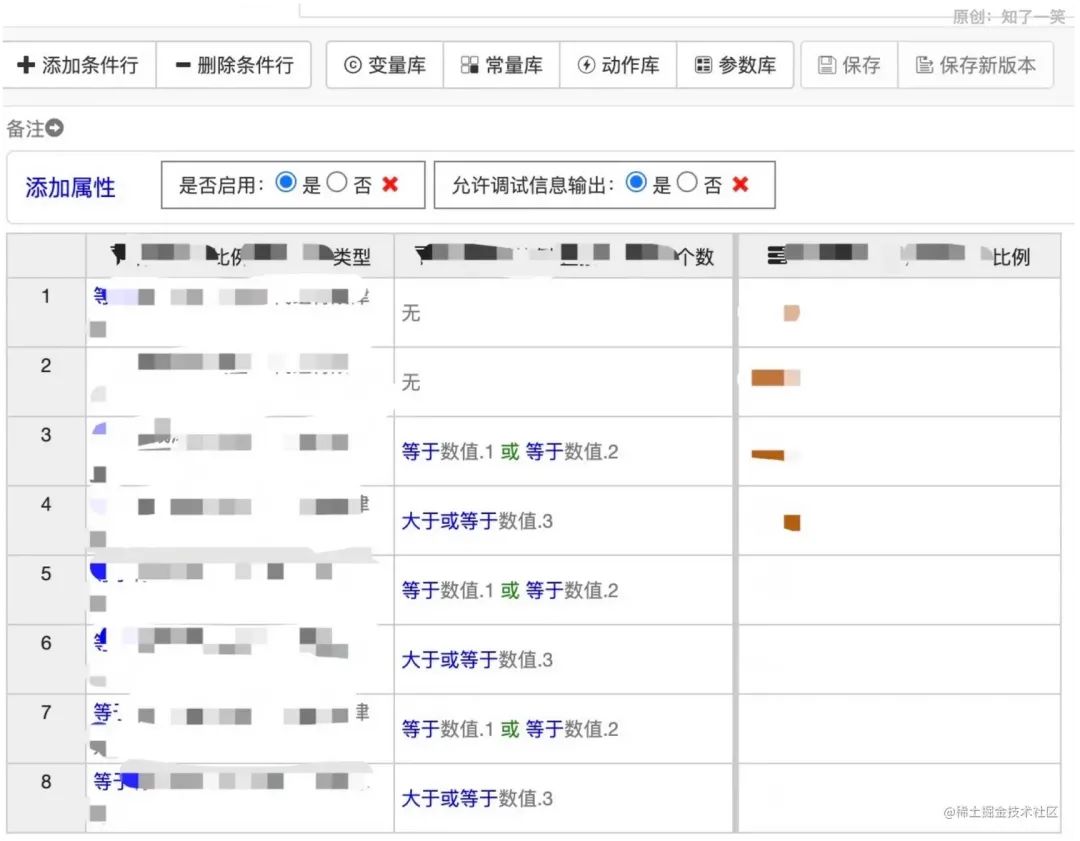
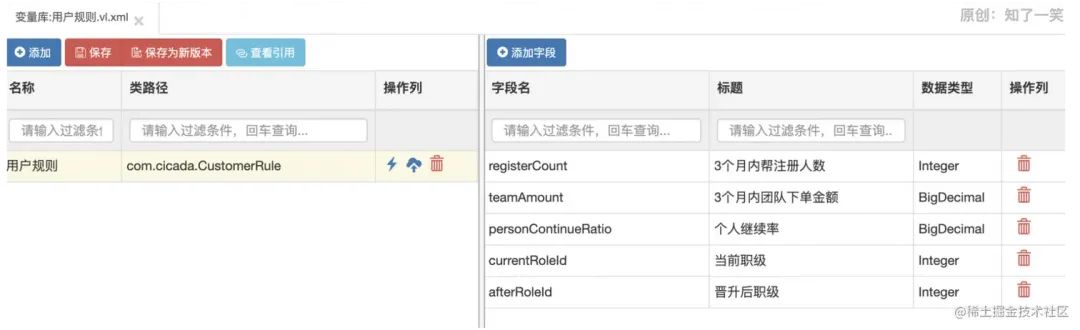
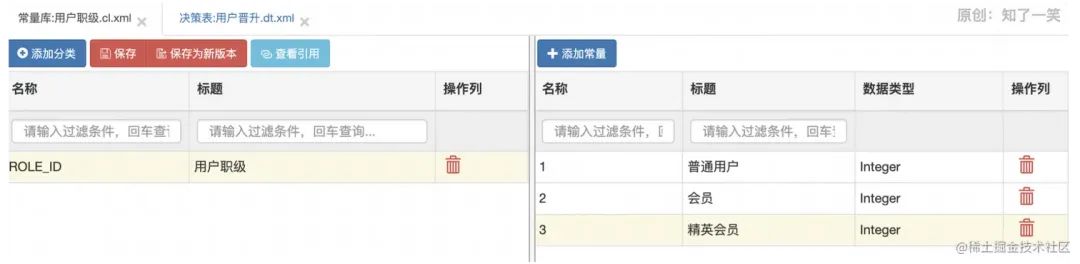
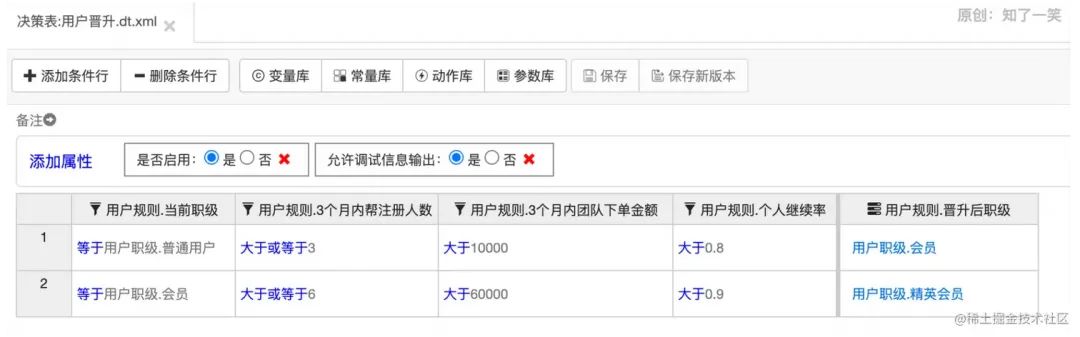
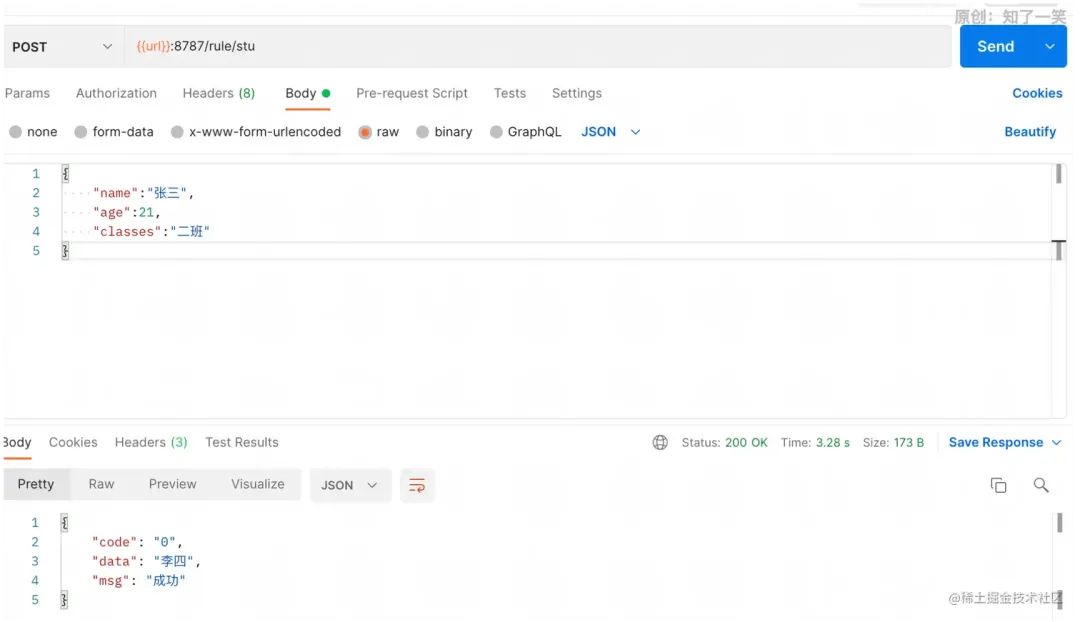 请求接口,最终参数符合配置的条件,返回“那么”中配置的输出结果。
请求接口,最终参数符合配置的条件,返回“那么”中配置的输出结果。