快乐分享,Java干货及时送达👇
打开浏览器访问查资料
面试总得有几个和所求岗位相关的项目,如果应届生、转行的童鞋没有项目,就靠简单的javaSE或者其他语言基础那只能说“你太难了”。
通过 Github ,你可以很方便的下载自己需要的项目,了解实时热点的项目,通过对优秀的开源项目的学习,更好的进行学习与提高

那么如何使用Github高效率的查找项目呢?这篇文章带你了解一下
仓库分几种?
-
本地仓库:建立在本地的文件夹。 -
远程仓库:建立在互联网的服务器内的文件夹。
分布式版本控制系统
-
配有两个仓库,在你的电脑上有一个 本地仓库 ,在远程的服务器上有一个 远程仓库 。 -
我们在提交文件的时候会先提交到本地仓库,然后在有网络的情况下,再从本地仓库提交到网络上的远程仓库。 -
Git 就是一个典型的分布式版本控制系统 -
Github就担任了上述的远程仓库这一角色,就是一个存放在外网服务器上的一个文件夹。并且Github是免费的开源的托管平台
什么是Git
Git (读音为/gɪt/)是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。
GitHub是一个面向开源及私有软件项目的托管平台,因为只支持git 作为唯一的版本库格式进行托管,故名GitHub。

Github常用词含义
-
watch:会持续收到项目的动态 -
fork:复制某个项目到自己的仓库 -
star:点赞数,表示对该项目表示认可,点赞数越多的项目一般越火 -
clone:将项目下载到本地 -
follow:关注你感兴趣的作者,会收到他们的动态
一个完整的项目界面
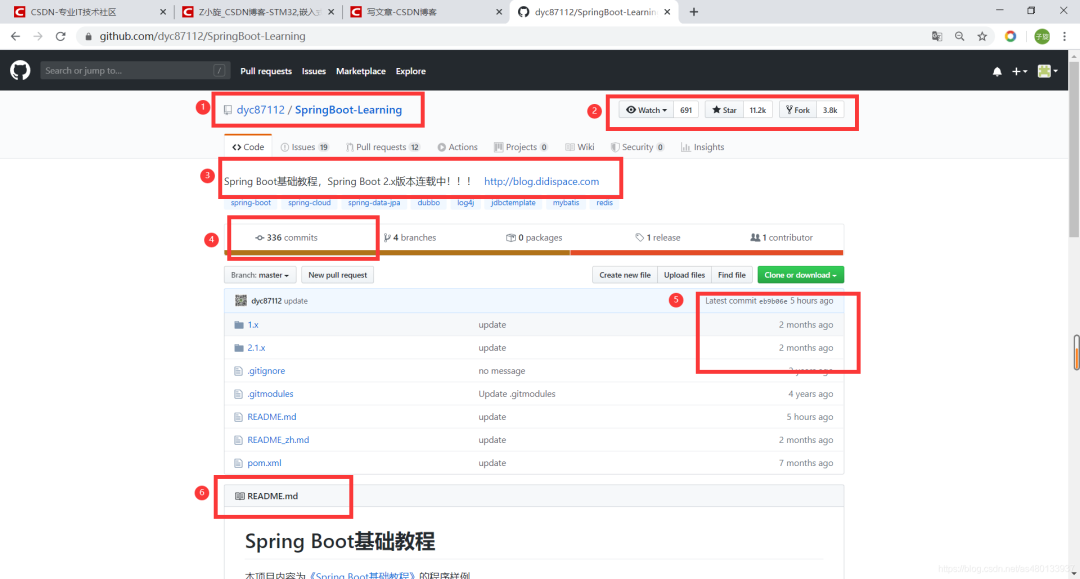
-
① 此处是项目作者名/项目名 -
② 此处是项目的点赞数,和fock数,越火的项目点赞和fock就会越多 -
③ 项目的Description 和Website 和tags 也就是项目的说明和标签, 通过此处你可以一眼了解该项目的功能和简介 -
④ 项目的commits提交数 ,一般比较好的项目,维护会比较频繁,更新也会频繁,提交数就会多 -
⑤项目提交时间, 通过这里你可以看到项目的提交时间,防止自己下载了一些远古项目 -
⑥ README.md README.md文件是一个项目的入门手册,里面介绍了整个项目的使用、功能等等。所以README文件写得好不好,关系到这个项目能不能更容易的被其他人了解和使用。
使用Github搜索项目
一般人用Github的步骤 直接搜索,选择一下Languages 设置下项目排序顺序 就直接下载
然后就是克隆仓库,阅读md,看项目源代码,看不懂,关闭项目,删除。
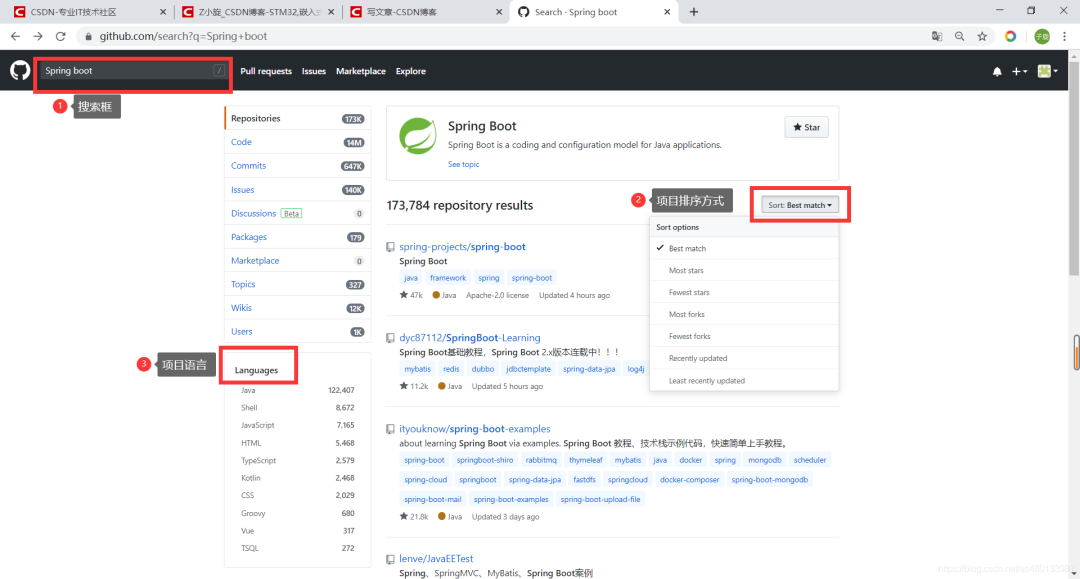
这样是很难找到真正适合自己的项目的,
GitHub里面有很多有价值的开源项目和代码,如何在海量的代码库中搜索我们需要的信息,那么接下来将带你了解下如何利用GitHub强大的搜索功能,来找到适合自己的项目
GitHub的高级搜索
GitHub有高级搜索功能,search/advanced可以输入关键字、代码库大小、包含作者、代码语、代码包含后缀文件名等。


这里我们假设正要学习 Spring Boot,要找一个 Spring Boot的 Demo 来进行参考学习。
精准搜索仓库标题、仓库描述、README
in关键词限制搜索范围
按照项目名/仓库名搜索(大小写不敏感)
(1)公式
-
in:name xxx项目名包含xxx -
in:description xxx项目描述包含xxx -
in:readme xxx项目介绍文档里含有xxx
比如我搜索项目名里含有 Spring Boot 的 in:name Spring Boot
会发现项目数量由17W变成了11W
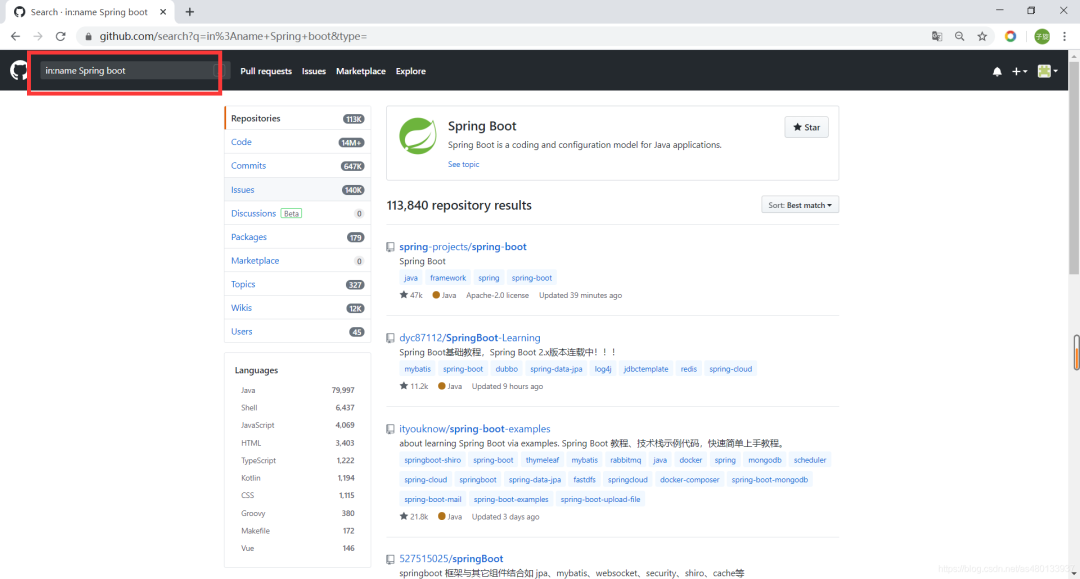
搜索项目描述里含有 Spring Boot 的 in:description Spring Boot

stars或fork数量去查找
一个项目 star 数的多少,一般代表该项目的受欢迎程度 越受欢迎的项目,star数和fork数一定也不会少
(1)公式
-
stars:>xxx stars数大于xxx -
stars:xx..xx stars数在xx…xx之间 -
forks:>xxx forks数大于xxx -
forks:xx..xx forks数在xx…xx之间
查找star数大于等于5000的springboot项目
spring boot stars:>=5000
查找fork数大于500的springcloud项目
spring cloud forks:>500
查找fork在100到200之间并且stars数在80到100之间的springboot项目
spring boot forks:100..200 stars:80..100
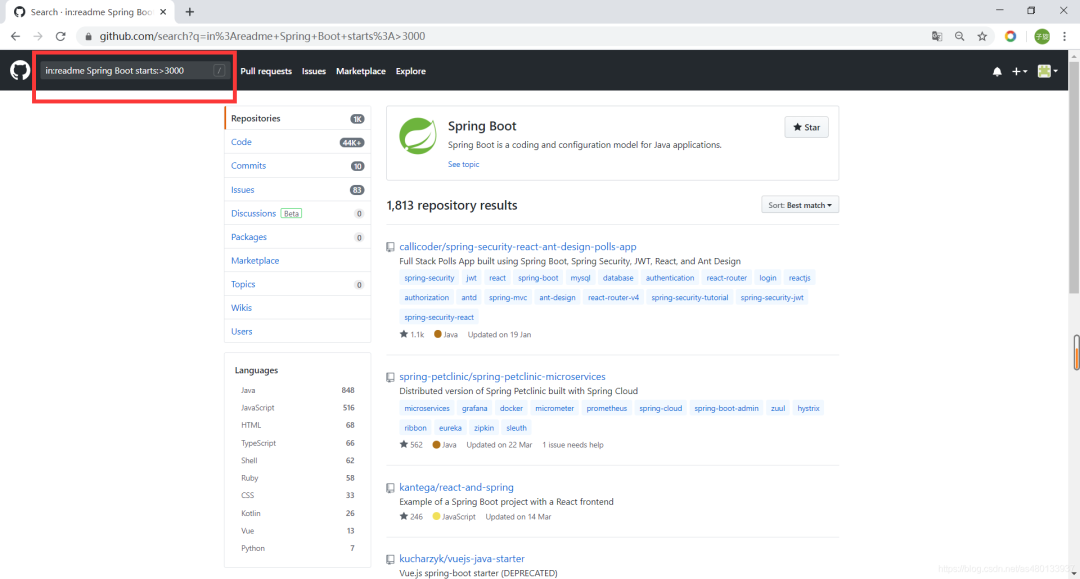
我们进一步缩小范围,Star数量过滤,要求Star数量大于3000
in:name spring boot starts :> 3000
可以看到只有一千多个项目供我们选择了
按照地区和语言进行搜索
很多时候我们的项目是要用我们会的语言,你找到了一个Python写的好项目,但是没学过Python,下载了也看不懂,同时,为了更好的阅读README.md帮助文档以及项目注释,我想很多同学都会想要下载中文的项目,当然英语顶呱呱的请忽略
(1)公式
-
location:地区 -
language:语言
语言为javaScript
language:javaScript
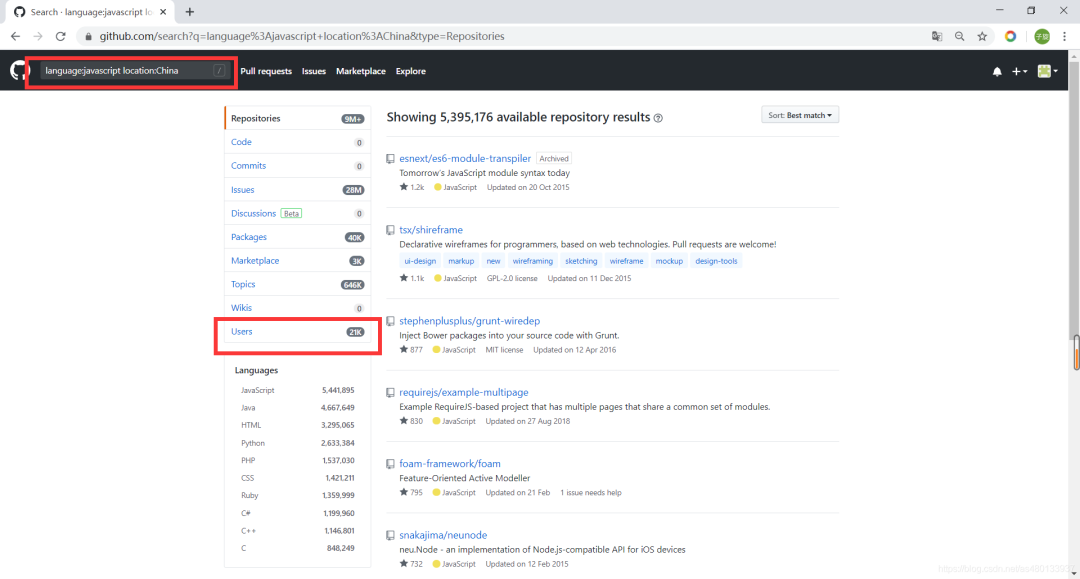
地区为china
location: China
如果你要寻找使用 javascript 语言的国产项目,整个搜索条件就是:language:javascript location:china,从搜索结果来看,我们找到了五百多万javascript 项目,近 21000 多名地区信息填写为 China 的 javascript 开发者,
根据仓库大小搜索
如果你只是想找一些小型的项目进行个人学习和开发,不想找特别复杂的,那么使用size关键字查找简单的 Demo,就成了你的首选
(1)公式
size:>= 数字
注意:100代表100Kb 单位为Kb
根据仓库是否在更新的搜索
寻找项目当然是想要找到最新的项目,而不是好久都没有更新的老项目了,
(1)公式
-
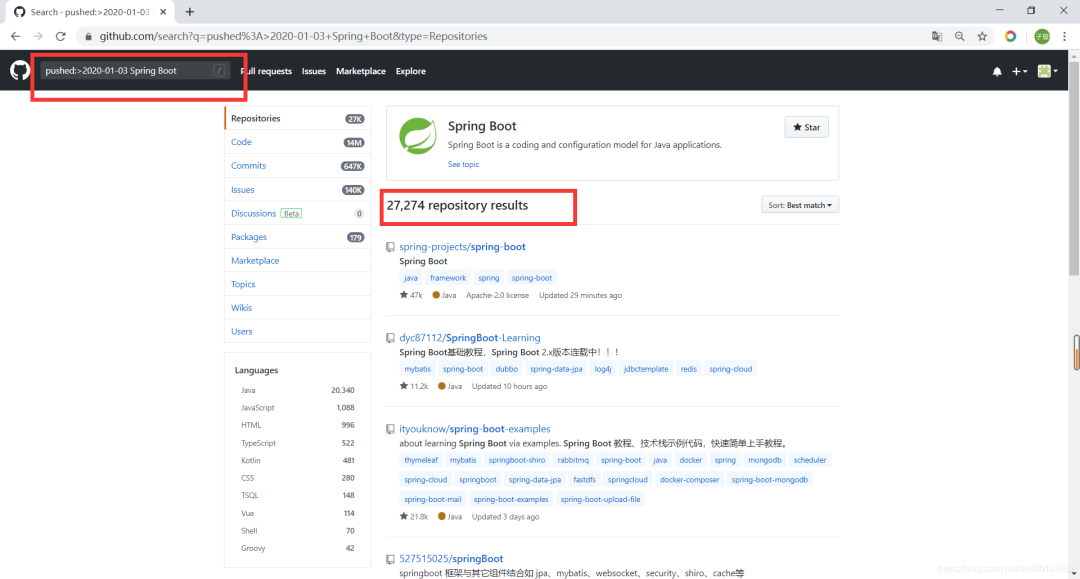
pushed:> YYYY-MM-DD最后上传日期大于YYYY-MM-DD -
created:> YYYY-MM-DD创建日期大于YYYY-MM-DD
比如我们想要寻找2020年最新更新的项目,可以用 pushed:>2020-01-03 Spring Boot ,这样子就可以找到今年一月份之后更新的最新项目
根据某个人或组织进行搜索
如果你想在GitHub 上找一下某个大神是不是提交了新的项目,可以对他们进行精准搜索
(1)公式
-
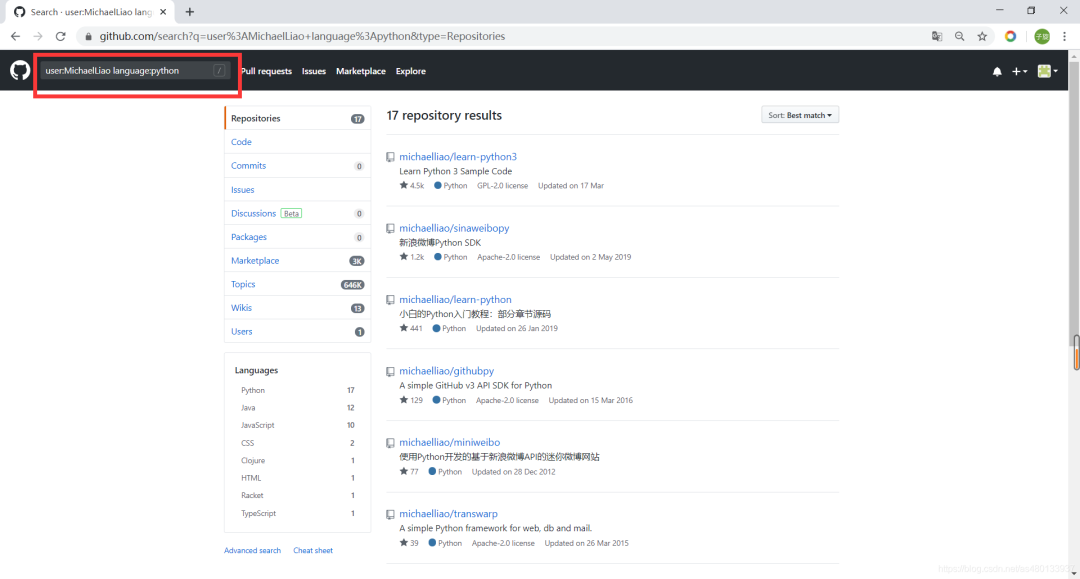
user: name查找某个用户 -
org: name查找某个组织 -
followers:>=xxx查找关注者数量超过xxx的开发者
比方说我们想要找一下廖雪峰老师的python开源项目
user:MichaelLiao language:python
根据仓库的LICENSE搜索
License是很多人容易忽略的一个问题
开源项目的License(项目授权协议) 有的开源项目作者明确禁止商用了,但是你不知情下载了,并且使用了,这就会很麻烦,“非常友好”的协议,比较出名的有这几种:BSD、MPL(Mozilla)、Apache、MIT。这些协议不但允许项目的使用者使用开源库,有些还允许对开源库进行修改并重新分发。因此用起来特别爽。上述这几个协议在细节上有些小差异,大伙儿可以去它们官网瞧一下。
以下这个网站,详细介绍了各个License的区别。
http://choosealicense.com/licenses/
(1)公式
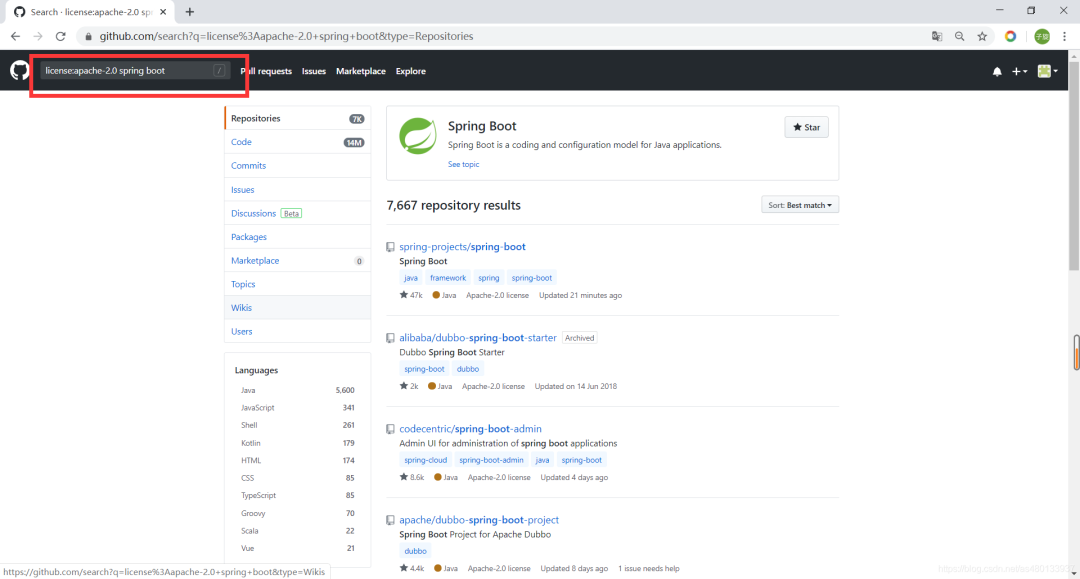
-license:对应协议
例如咱们要找协议是最为宽松的 Apache License 2 的代码,
license:apache-2.0 Spring Boot
awesome加强搜索
Awesome 似乎已经成为不少 GitHub 项目喜爱的命名之一,Awesome 往往整合了大量的同一领域的资料,让大家可以更好的学习。
(1)公式
awesome 关键字 awesome 系列一般是用来收集学习、工具、书籍类相关的项目
-
比如搜索优秀的python相关的项目,包括框架、教程等

awesome-python,这个库提供了各个领域常见的python库支持。整体看下来,几乎涵盖了所有的常见的计算机领域,
热门搜索(GitHub Trend 和 GitHub Topic)
GitHub Trend 页面总结了每天/每周/每月周期的热门 Repositories 和 Developers,你可以看到在某个周期处于热门状态的开发项目和开发者
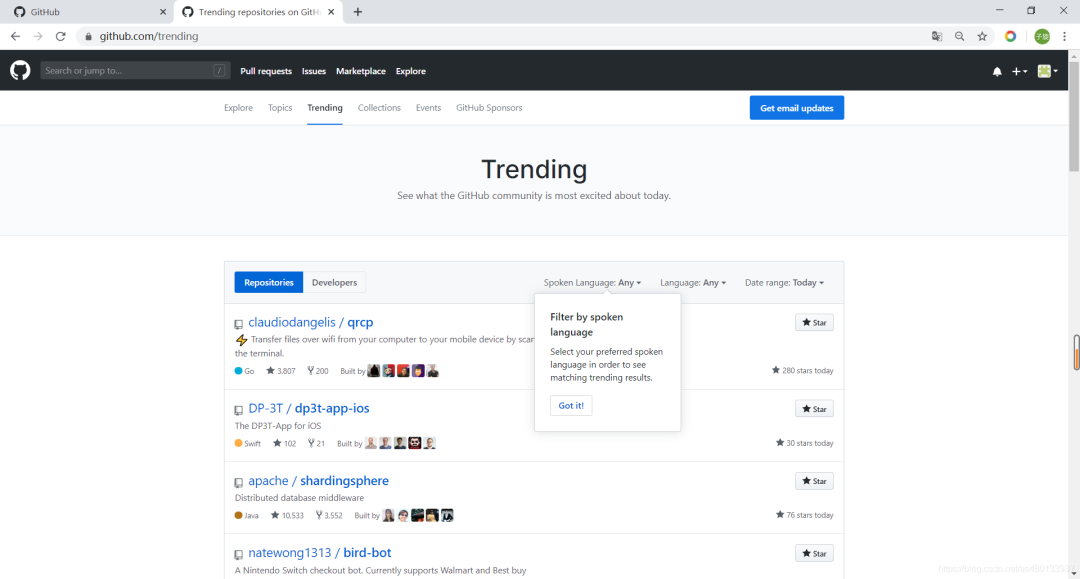
GitHub Topic 展示了最新和最流行的讨论主题,在这里你不仅能够看到开发项目,还能看到更多非开发技术的讨论主题,
作者:Z小旋
来源:blog.csdn.net/as480133937/article/
details/105611577

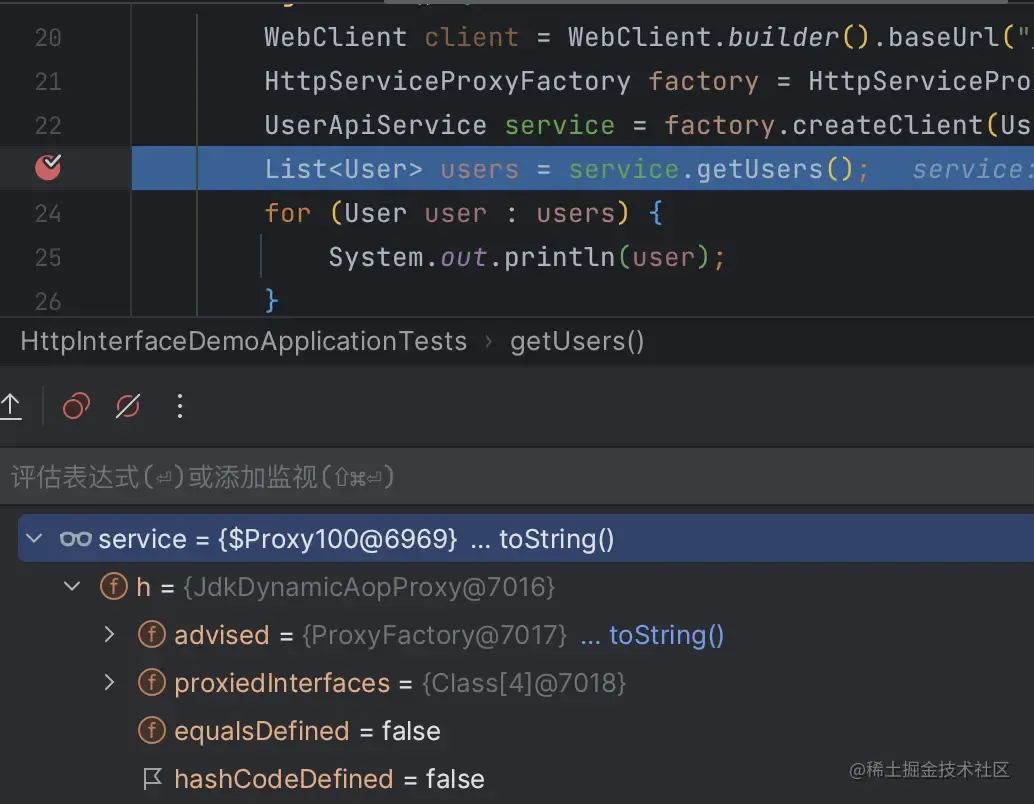

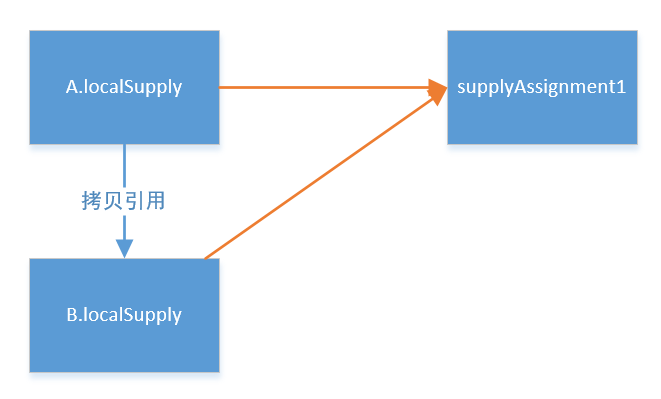
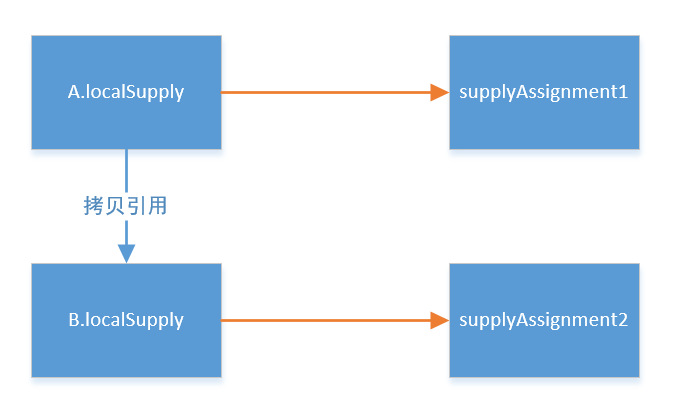

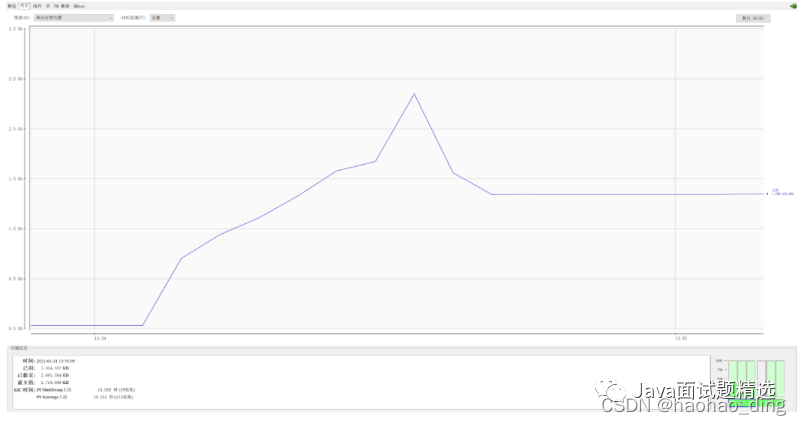
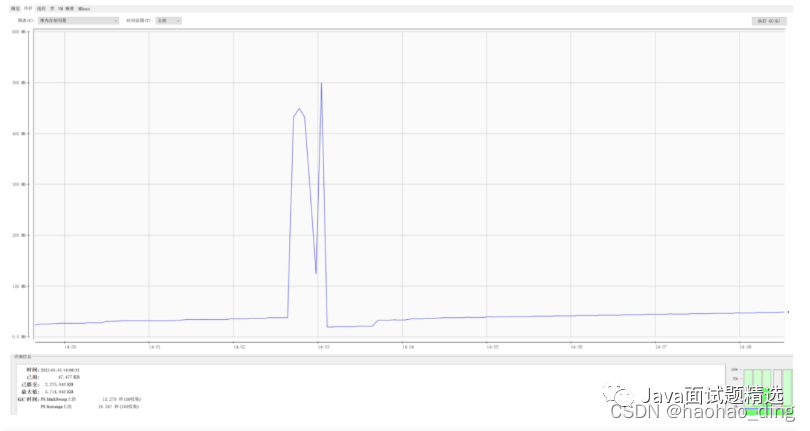

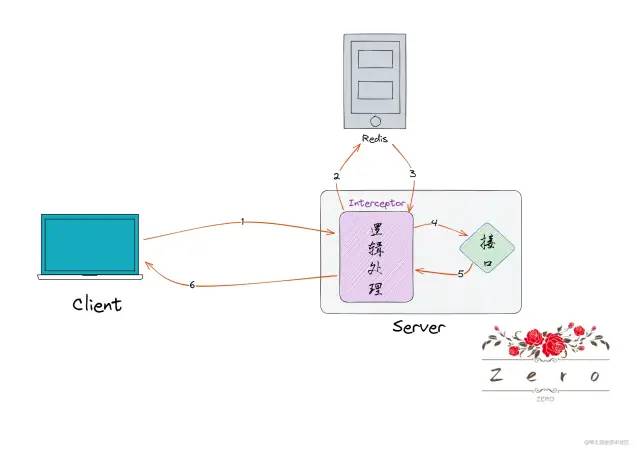
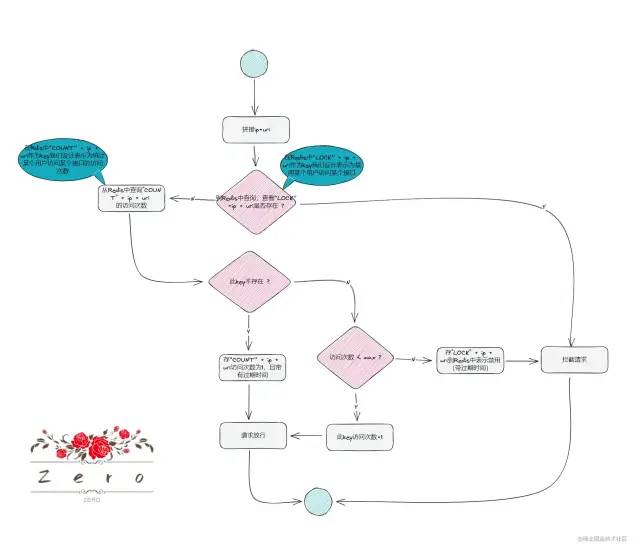
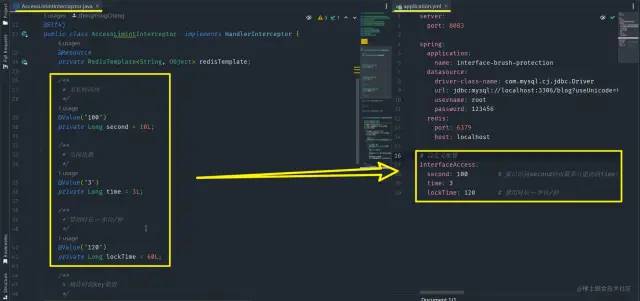
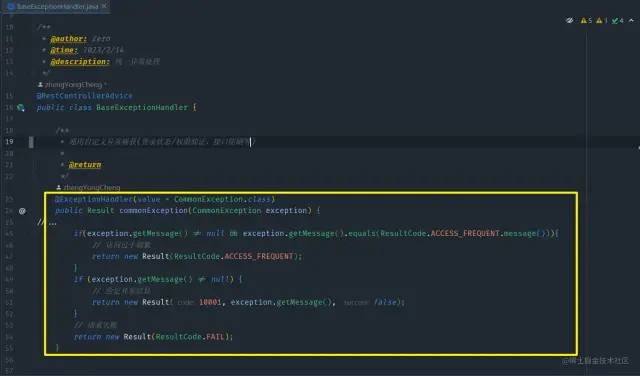
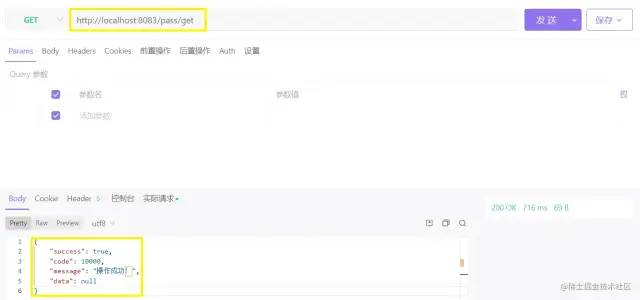
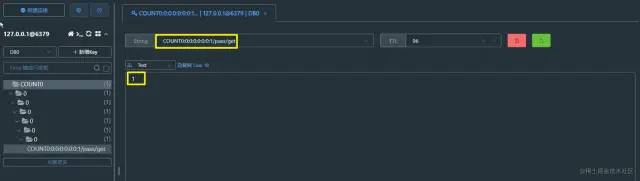
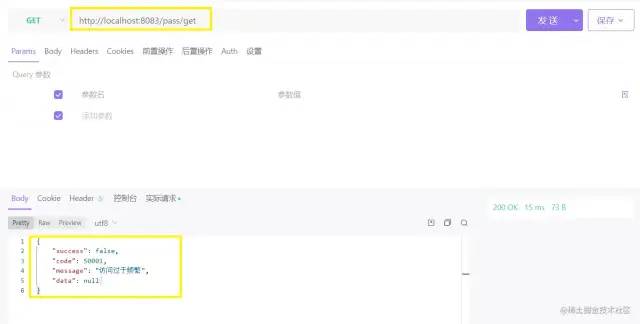

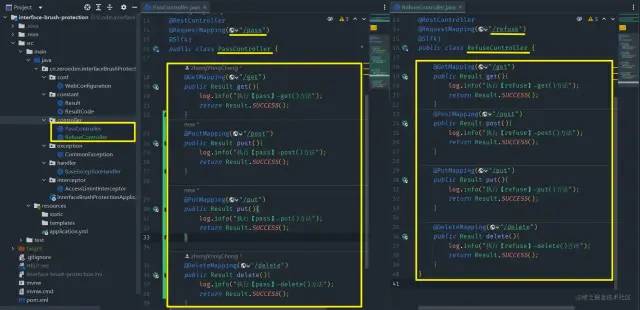
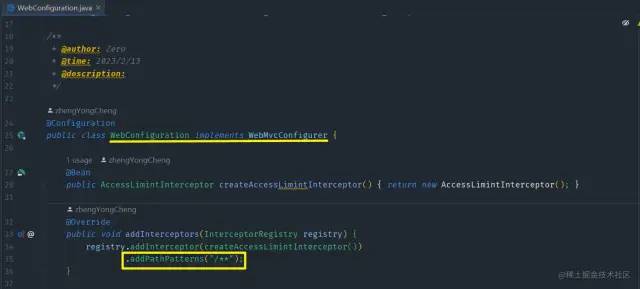

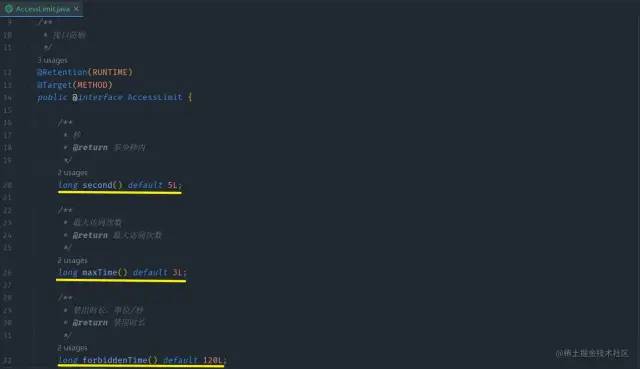
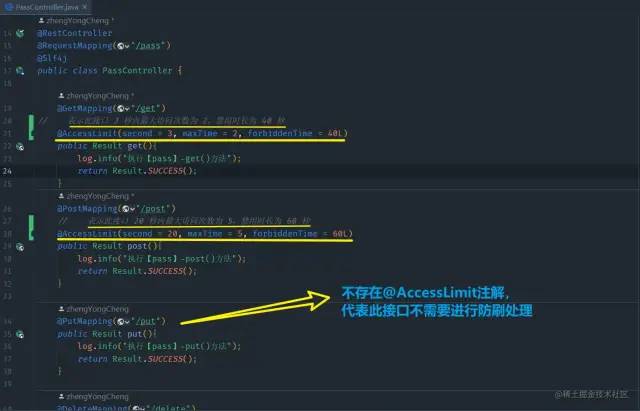




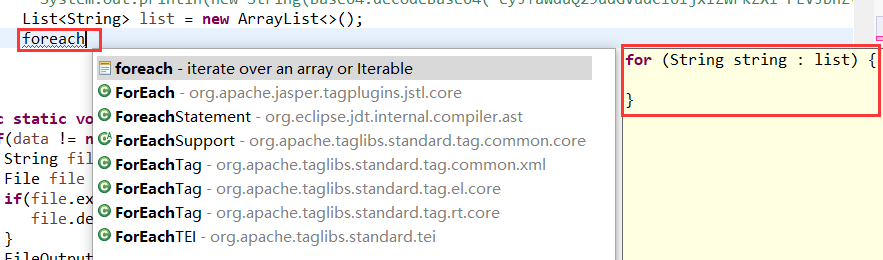
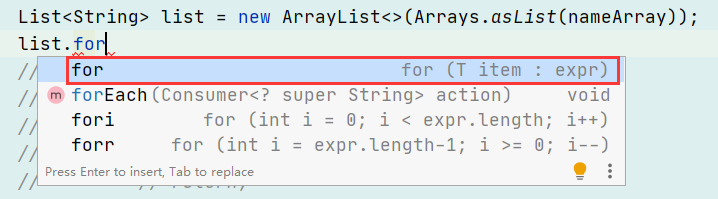

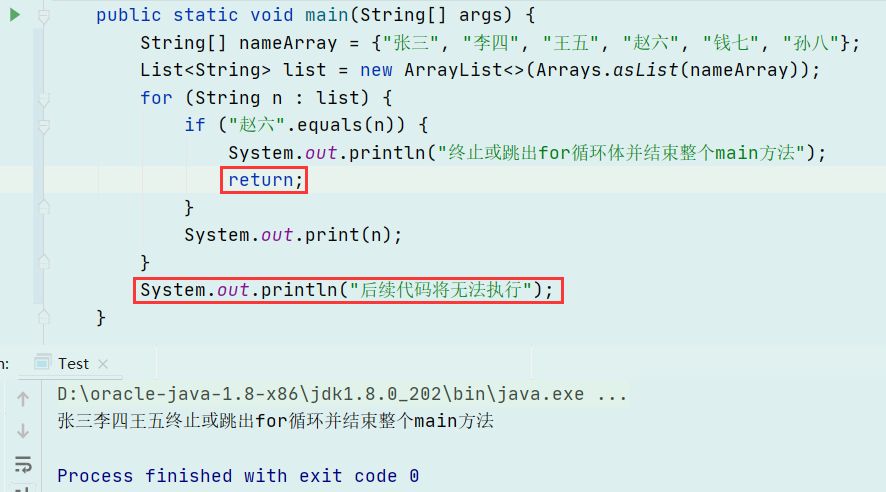
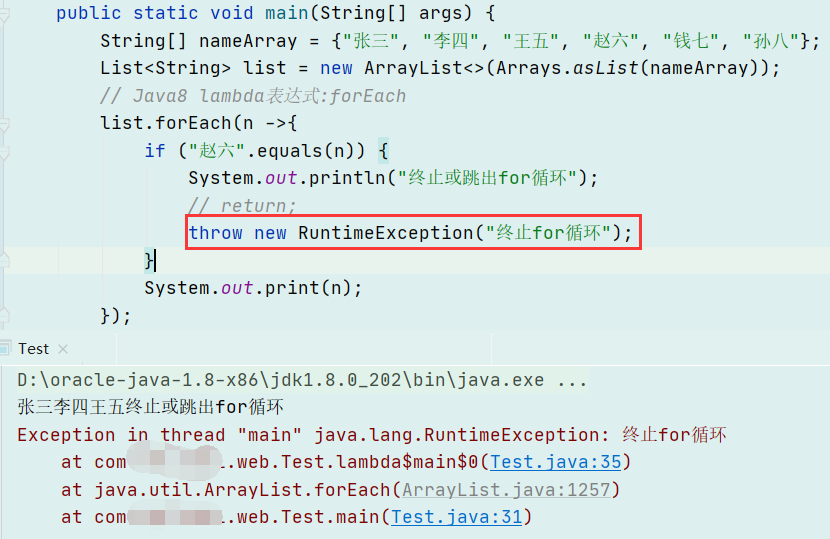

 整体截图
整体截图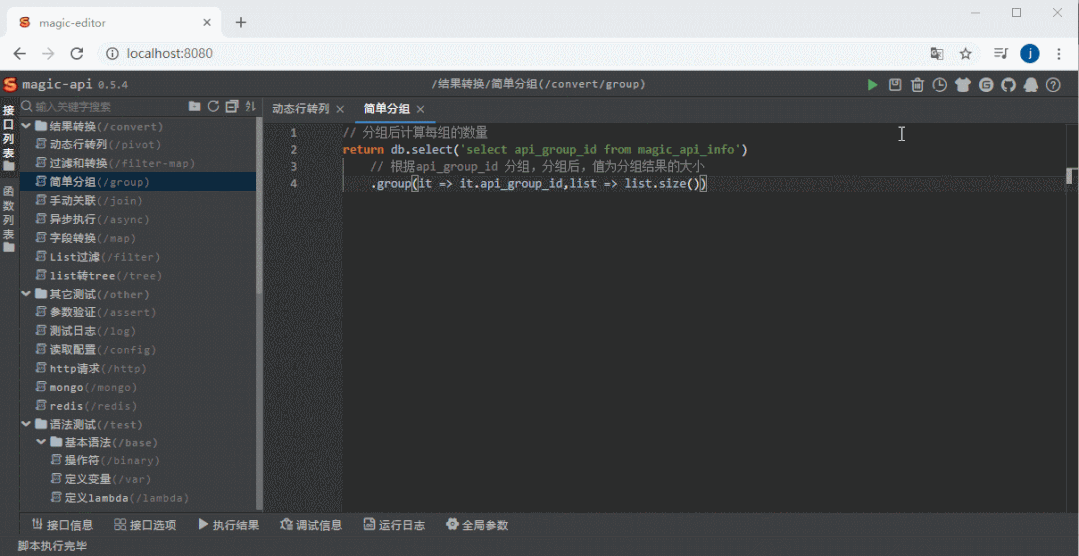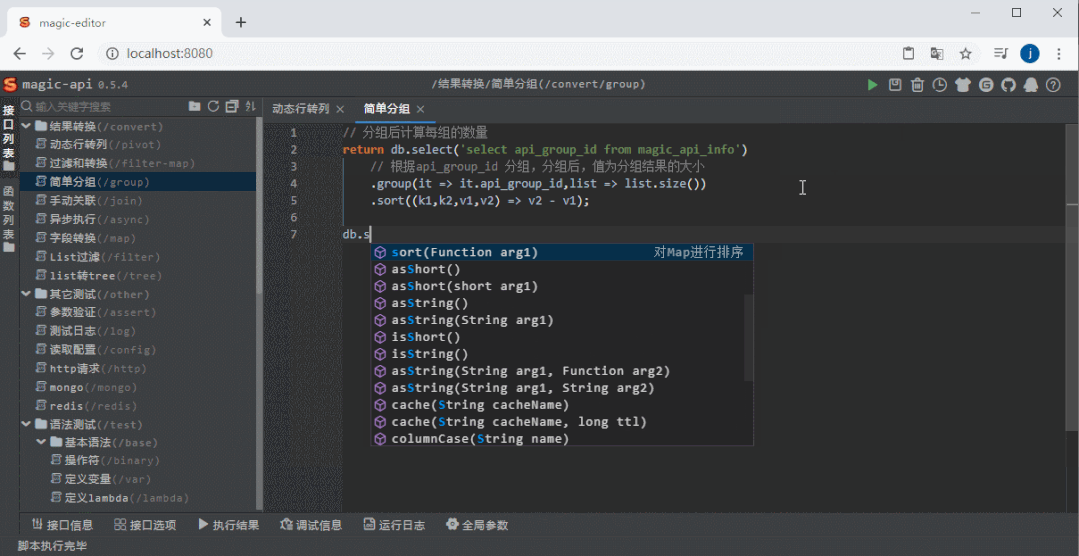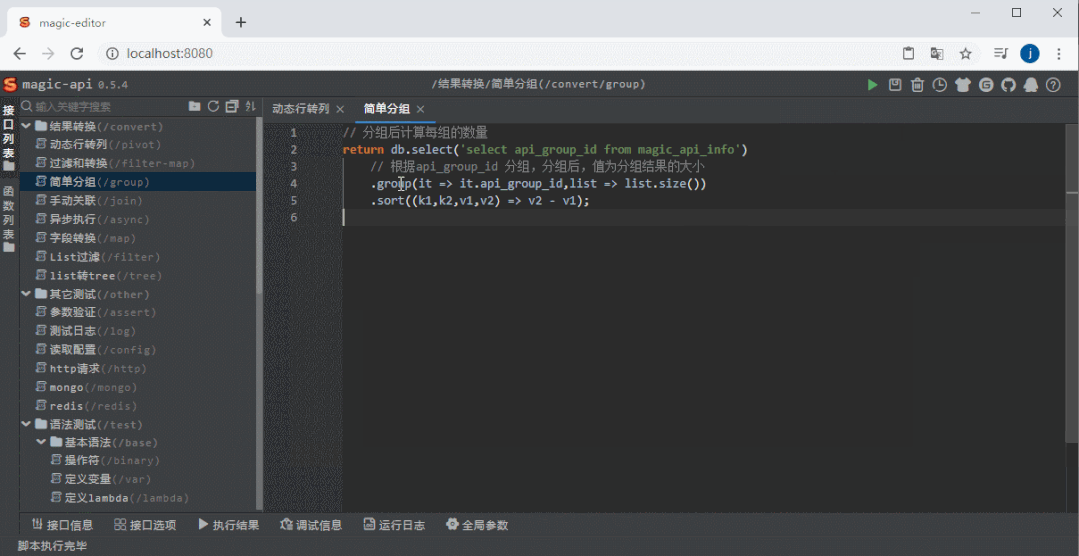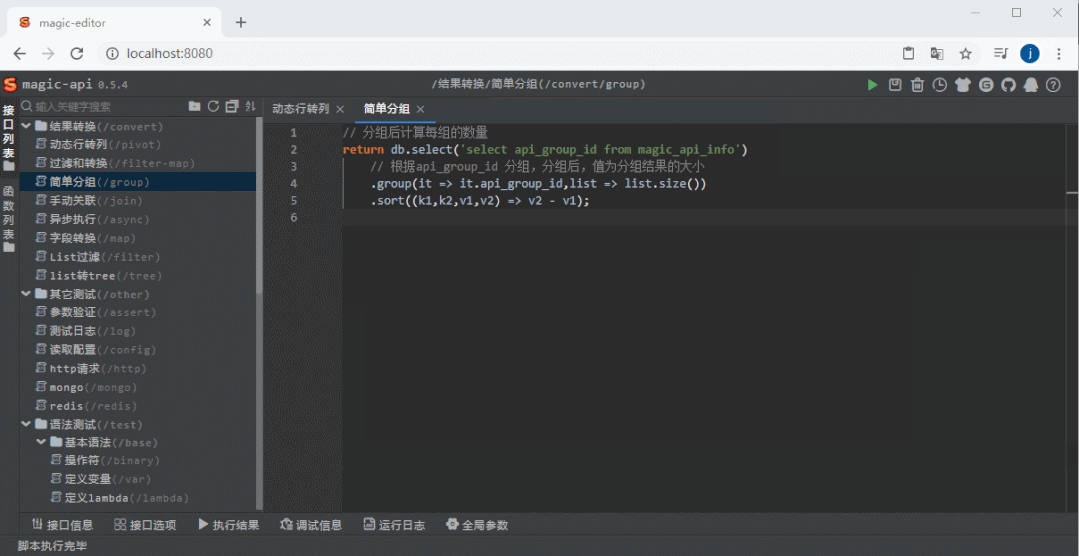 代码提示
代码提示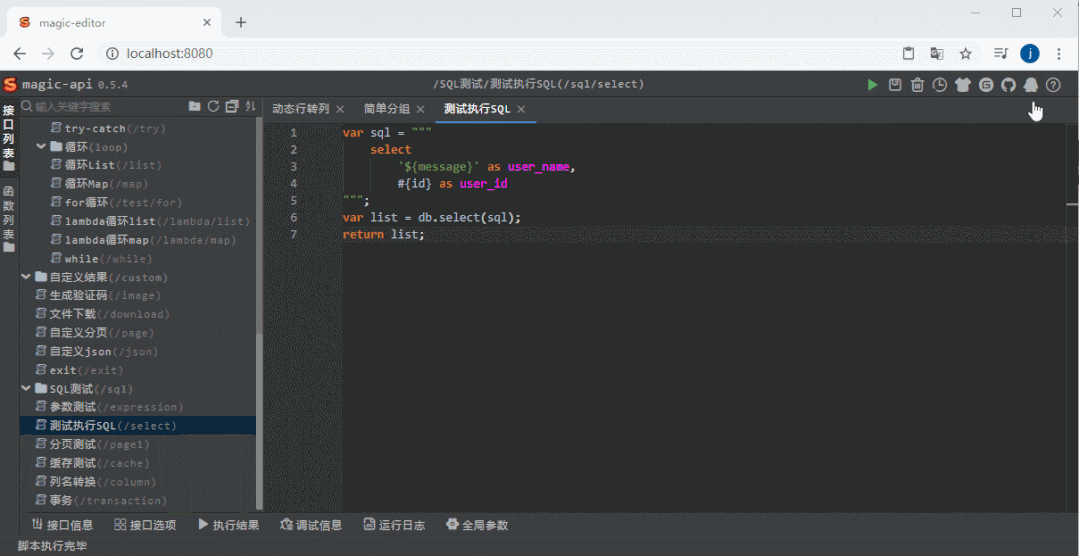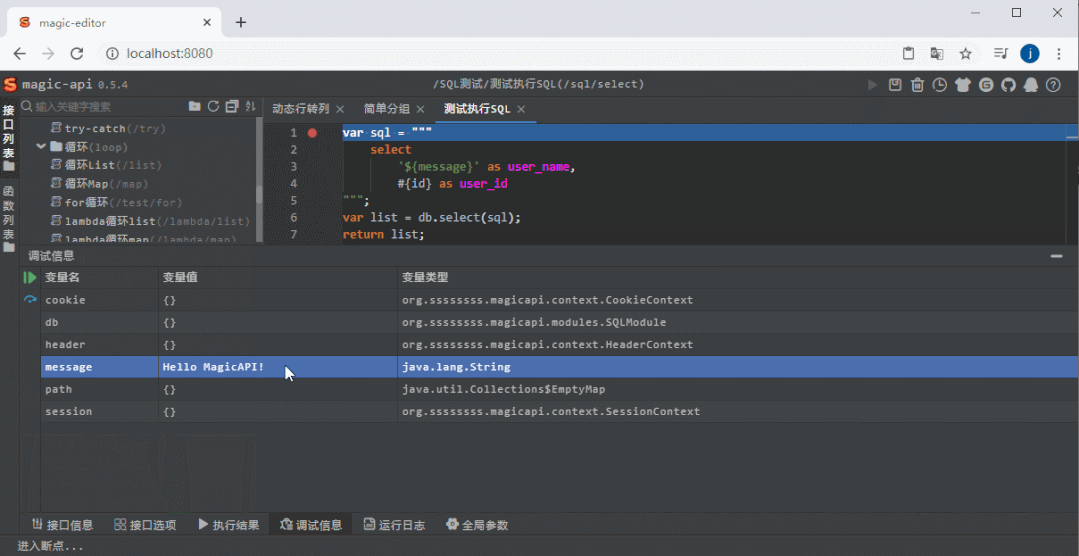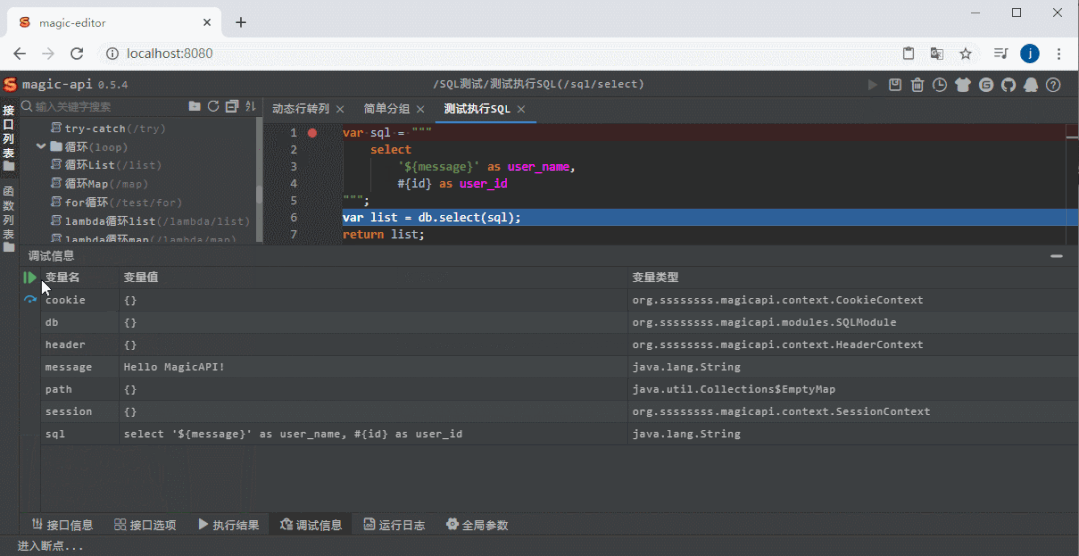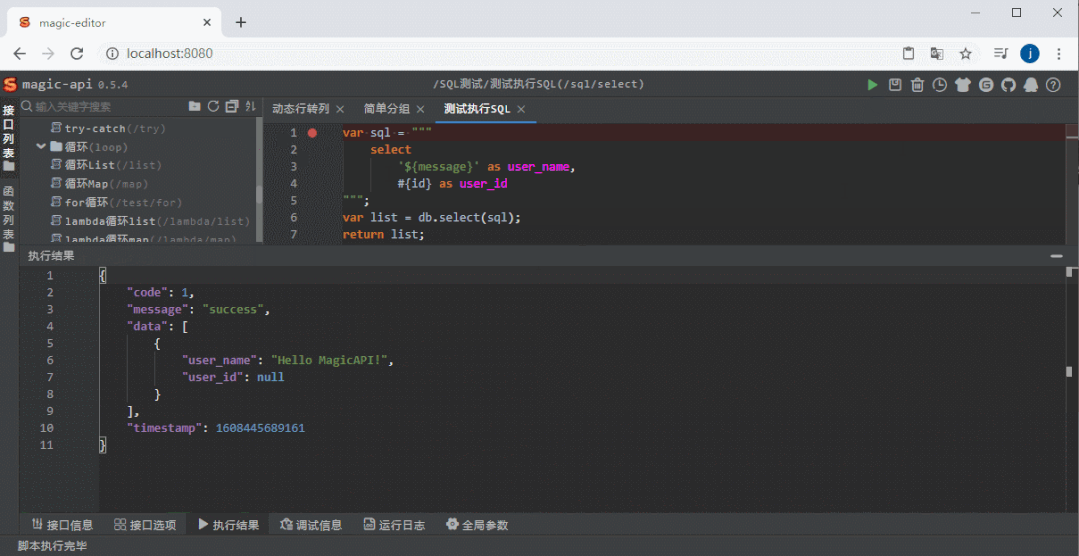 DEBUG
DEBUG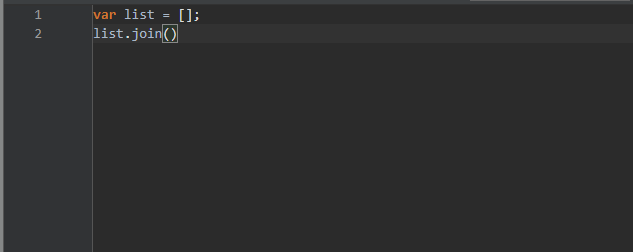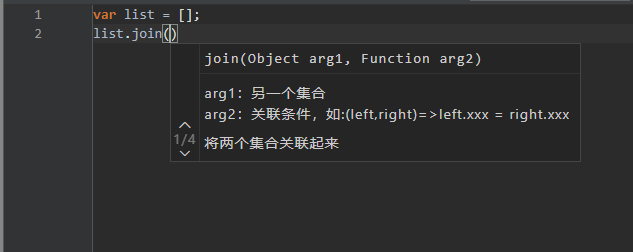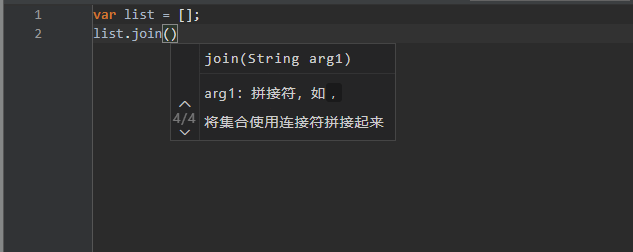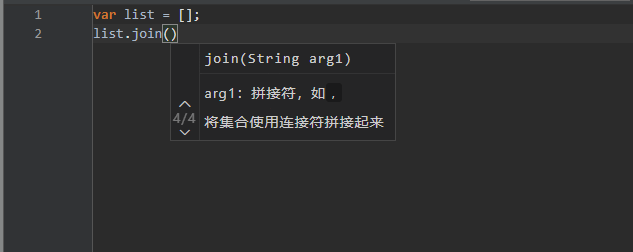 参数提示
参数提示 远程推送
远程推送 历史记录
历史记录 数据源
数据源 全局搜索
全局搜索