快乐分享,Java干货及时送达👇
 文章来源:https://blog.csdn.net/qq_48289488/article/details/121905018
文章来源:https://blog.csdn.net/qq_48289488/article/details/121905018
Podman
什么是Podman?

Podman 是一个开源的容器运行时项目,可在大多数 Linux 平台上使用。Podman 提供与 Docker 非常相似的功能。正如前面提到的那样,它不需要在你的系统上运行任何守护进程,并且它也可以在没有 root 权限的情况下运行。
Podman 可以管理和运行任何符合 OCI(Open Container Initiative)规范的容器和容器镜像。Podman 提供了一个与 Docker 兼容的命令行前端来管理 Docker 镜像。
Podman 官网地址:https://podman.io/
Podman和Docker的主要区别是什么?
-
dockers在实现CRI的时候,它需要一个守护进程,其次需要以root运行,因此这也带来了安全隐患。 -
podman不需要守护程序,也不需要root用户运行,从逻辑架构上,比docker更加合理。 -
在docker的运行体系中,需要多个daemon才能调用到OCI的实现RunC。 -
在容器管理的链路中,Docker Engine的实现就是dockerd -
daemon,它在linux中需要以root运行,dockerd调用containerd,containerd调用containerd-shim,然后才能调用runC。顾名思义shim起的作用也就是“垫片”,避免父进程退出影响容器的运训 -
podman直接调用OCI,runtime(runC),通过common作为容器进程的管理工具,但不需要dockerd这种以root身份运行的守护进程。 -
在podman体系中,有个称之为common的守护进程,其运行路径通常是/usr/libexec/podman/conmon,它是各个容器进程的父进程,每个容器各有一个,common的父则通常是1号进程。podman中的common其实相当于docker体系中的containerd-shim。
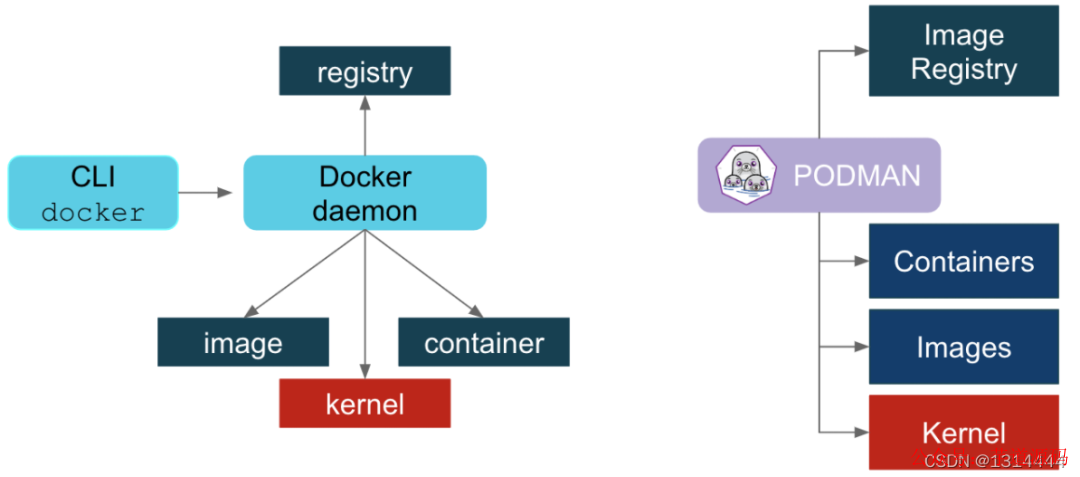
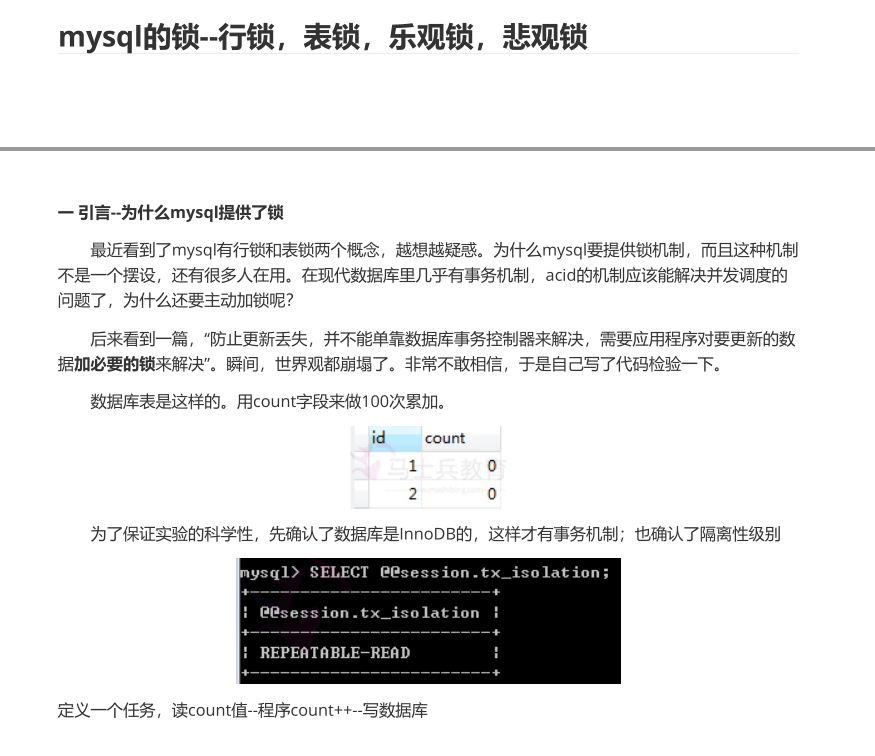
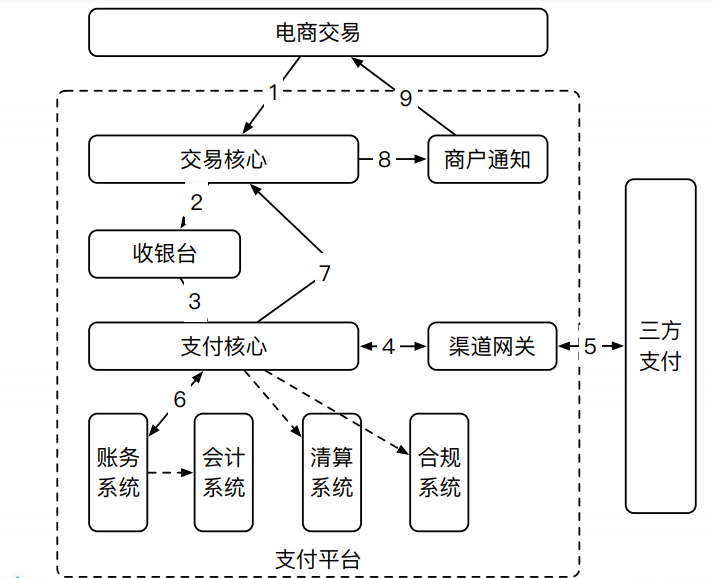
图中所体现的事情是,podman不需要守护进程,而dorker需要守护进程。在这个图的示意中,dorcker的containerd-shim与podman的common被归在Container一层。
Podman的使用与docker有什么区别?
podman的定位也是与docker兼容,因此在使用上面尽量靠近docker。在使用方面,可以分成两个方面来说,一是系统构建者的角度,二是使用者的角度。
在系统构建者方面,用podman的默认软件,与docker的区别不大,只是在进程模型、进程关系方面有所区别。如果习惯了docker几个关联进程的调试方法,在podman中则需要适应。可以通过pstree命令查看进程的树状结构。总体来看,podman比docker要简单。由于podman比docker少了一层daemon,因此重启的机制也就不同了。
在使用者方面,podman与docker的命令基本兼容,都包括容器运行时(run/start/kill/ps/inspect),本地镜像(images/rmi/build)、镜像仓库(login/pull/push)等几个方面。因此podman的命令行工具与docker类似,比如构建镜像、启停容器等。甚至可以通过alias
docker=podman可以进行替换。因此,即便使用了podman,仍然可以使用docker.io作为镜像仓库,这也是兼容性最关键的部分。
Podman常用命令
容器
podman run 创建并启动容器
podman start 启动容器
podman ps 查看容器
podman stop 终止容器
podman restart 重启容器
podman attach 进入容器
podman exec 进入容器
podman export 导出容器
podman import 导入容器快照
podman rm 删除容器
podman logs 查看日志
镜像
podman search 检索镜像
podman pull 获取镜像
podman images 列出镜像
podman image Is 列出镜像
podman rmi 删除镜像
podman image rm 删除镜像
podman save 导出镜像
podman load 导入镜像
podmanfile 定制镜像(三个)
podman build 构建镜像
podman run 运行镜像
podmanfile 常用指令(四个)
COPY 复制文件
ADD 高级复制
CMD 容器启动命令
ENV 环境变量
EXPOSE 暴露端口
部署 Podman
//安装podman
[root@localhost ~]# yum -y install podman
Podman 加速器
版本7配置加速器
//仓库配置
[root@localhost ~]# vim /etc/containers/registries.conf
[registries.search]
#registries = ["registry.access.redhat.com", "registry.redhat.io", "docker.io"] #这个是查找,从这三个地方查找
registries = ["docker.io"] #如果只留一个,则只在一个源里查找
[[docker.io]]
location="j3m2itm3.mirror.aliyuncs.com"
版本8配置加速器
#unqualified-search-registries = ["registry.fedoraproject.org", "registry.access.redhat.com", "registry.centos.org", "docker.io"] #直接注释掉
unqualified-search-registries = ["docker.io"] #添加一个docker.io
[[registry]]
prefix = "docker.io"
location = "j3m2itm3.mirror.aliyuncs.com" (不用加https:// 直接加地址)
使用 Podman
使用 Podman 非常的简单,Podman 的指令跟 Docker 大多数都是相同的。下面我们来看几个常用的例子:
运行一个容器
[root@localhost ~]# podman run -d --name httpd docker.io/library/httpd
Trying to pull docker.io/library/httpd...
Getting image source signatures
Copying blob e5ae68f74026 done
Copying blob d3576f2b6317 done
Copying blob bc36ee1127ec done
Copying blob f1aa5f54b226 done
Copying blob aa379c0cedc2 done
Copying config ea28e1b82f done
Writing manifest to image destination
Storing signatures
0492e405b9ecb05e6e6be1fec0ac1a8b6ba3ff949df259b45146037b5f355035
//查看镜像
[root@localhost ~]# podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/library/httpd latest ea28e1b82f31 11 days ago 148 MB
列出运行的容器
[root@localhost ~]# podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0492e405b9ec docker.io/library/httpd:latest httpd-foreground About a minute ago Up About a minute ago httpd
注意:如果在ps命令中添加-a,Podman 将显示所有容器。
检查正在运行的容器
您可以“检查”正在运行的容器的元数据和有关其自身的详细信息。我们甚至可以使用 inspect 子命令查看分配给容器的 IP 地址。由于容器以无根模式运行,因此未分配 IP 地址,并且该值将在检查的输出中列为“无”。
[root@localhost ~]# podman inspect -l | grep IPAddress":
"SecondaryIPAddresses": null,
"IPAddress": "10.88.0.5",
[root@localhost ~]# curl 10.88.0.5
It works!
注意:-l 是最新容器的便利参数。您还可以使用容器的 ID 代替 -l。
查看一个运行中容器的日志
选项
--latest #最近的
[root@localhost ~]# podman logs --latest
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.88.0.5. Set the 'ServerName' directive globally to suppress this message
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.88.0.5. Set the 'ServerName' directive globally to suppress this message
[Mon Dec 13 15:17:53.690844 2021] [mpm_event:notice] [pid 1:tid 140665160166720] AH00489: Apache/2.4.51 (Unix) configured -- resuming normal operations
[Mon Dec 13 15:17:53.690946 2021] [core:notice] [pid 1:tid 140665160166720] AH00094: Command line: 'httpd -D FOREGROUND'
10.88.0.1 - - [13/Dec/2021:15:19:48 +0000] "GET / HTTP/1.1" 200 45
10.88.0.1 - - [13/Dec/2021:15:20:47 +0000] "GET / HTTP/1.1" 200 45
查看一个运行容器中的进程资源使用情况,可以使用top观察容器中的 nginx pid
语法:
podman top
[root@localhost ~]# podman top httpd
USER PID PPID %CPU ELAPSED TTY TIME COMMAND
root 1 0 0.000 15m38.599711321s ? 0s httpd -DFOREGROUND
www-data 7 1 0.000 15m38.599783256s ? 0s httpd -DFOREGROUND
www-data 8 1 0.000 15m38.599845342s ? 0s httpd -DFOREGROUND
www-data 9 1 0.000 15m38.599880444s ? 0s httpd -DFOREGROUND
停止一个运行中的容器
[root@localhost ~]# podman stop --latest
2f3edf712621d3a41e03fa8c7f6a5cdba56fbbad43a7a59ede26cc88f31006c4
[root@localhost ~]# podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
删除一个容器
[root@localhost ~]# podman rm --latest
2f3edf712621d3a41e03fa8c7f6a5cdba56fbbad43a7a59ede26cc88f31006c4
[root@localhost ~]# podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
以上这些特性基本上都和 Docker 一样,Podman 除了兼容这些特性外,还支持了一些新的特性。
上传镜像
例如,如果我们想在 docker.io 上分享我们新建的 Nginx 容器镜像,这很容易。首先登录码头:
[root@localhost nginx]# tree
.
├── Dockerfile
└── files
└── nginx-1.20.1.tar.gz
[root@localhost nginx]# cat Dockerfile
FROM docker.io/library/centos
ENV PATH /usr/local/nginx/sbin:$PATH
ADD files/nginx-1.20.1.tar.gz /usr/src
RUN useradd -r -M -s /sbin/nologin nginx &&
yum -y install pcre-devel openssl openssl-devel gd-devel gcc gcc-c++ make &&
mkdir -p /var/log/nginx &&
cd /usr/src/nginx-1.20.1 &&
./configure
--prefix=/usr/local/nginx
--user=nginx
--group=nginx
--with-debug
--with-http_ssl_module
--with-http_realip_module
--with-http_image_filter_module
--with-http_gunzip_module
--with-http_gzip_static_module
--with-http_stub_status_module
--http-log-path=/var/log/nginx/access.log
--error-log-path=/var/log/nginx/error.log &&
make && make install
CMD ["nginx","-g","daemon off"]
[root@localhost nginx]# podman build -t nginx .
// 修改镜像名
[root@localhost ~]# podman tag docker.io/library/nginx:latest docker.io/1314444/test:latest
// 登录并上传镜像
[root@localhost ~]# podman login docker.io // 需要告诉其要登录到docker仓库
[root@localhost ~]# podman login docker.io
Username: 1314444 #账户
Password: ******** #密码
Login Succeeded!
[root@localhost nginx]# podman push docker.io/1314444/test:latest //上传镜像
Getting image source signatures
Copying blob 38c40d6c2c85 done
Copying blob fee76a531659 done
Copying blob c2adabaecedb done
Copying config 7f3589c0b8 done
Writing manifest to image destination
Copying config 7f3589c0b8 done
Writing manifest to image destination
Storing signatures
//请注意,我们将四层推送到我们的注册表,现在可供其他人共享。快速浏览一下:
[root@localhost ~]# podman inspect 1314444/test:nginx
//输出:
[
{
"Id": "7f3589c0b8849a9e1ff52ceb0fcea2390e2731db9d1a7358c2f5fad216a48263",
"Digest": "sha256:7822b5ba4c2eaabdd0ff3812277cfafa8a25527d1e234be028ed381a43ad5498",
"RepoTags": [
"docker.io/1314444/test:nginx",
......
总而言之,Podman 使查找、运行、构建和共享容器变得容易。
配置别名
如果习惯了使用 Docker 命令,可以直接给 Podman 配置一个别名来实现无缝转移。你只需要在 .bashrc 下加入以下行内容即可:
[root@localhost ~]# echo "alias docker=podman" >> .bashrc
source .bashrc
[root@localhost ~]# alias
alias cp='cp -i'
alias docker='podman'
.......
用户操作
在允许没有root特权的用户运行Podman之前,管理员必须安装或构建Podman并完成以下配置
cgroup V2Linux内核功能允许用户限制普通用户容器可以使用的资源,如果使用cgroupV2启用了运行Podman的Linux发行版,则可能需要更改默认的OCI运行时。某些较旧的版本runc不适用于cgroupV2,必须切换到备用OCI运行时crun。
[root@localhost ~]# yum -y install crun //centos8系统自带
[root@localhost ~]# vi /usr/share/containers/containers.conf
446 # Default OCI runtime
447 #
448 runtime = "crun" //取消注释并将runc改为crun
[root@localhost ~]# podman run -d --name web -p 80:80 docker.io/library/nginx
c8664d2e43c872e1e5219f82d41f63048ed3a5ed4fb6259c225a14d6c243677f
[root@localhost ~]# podman inspect web | grep crun
"OCIRuntime": "crun",
"crun",
安装slirp4netns和fuse-overlayfs
在普通用户环境中使用Podman时,建议使用fuse-overlayfs而不是VFS文件系统,至少需要版本0.7.6。现在新版本默认就是了。
[root@localhost ~]# yum -y install slirp4netns
[root@localhost ~]# yum -y install fuse-overlayfs
[root@localhost ~]# vi /etc/containers/storage.conf
77 mount_program = "/usr/bin/fuse-overlayfs" //取消注释
/ etc / subuid和/ etc / subgid配置
Podman要求运行它的用户在/ etc / subuid和/ etc / subgid文件中列出一系列UID,shadow-utils或newuid包提供这些文件
[root@localhost ~]# yum -y install shadow-utils
可以在/ etc / subuid和/ etc / subgid查看,每个用户的值必须唯一且没有任何重叠。
[root@localhost ~]# useradd zz
[root@localhost ~]# cat /etc/subuid
zz:100000:65536
[root@localhost ~]# cat /etc/subgid
zz:100000:65536
// 启动非特权ping
[root@localhost ~]# sysctl -w "net.ipv4.ping_group_range=0 200000" //大于100000这个就表示tom可以操作podman
net.ipv4.ping_group_range = 0 200000
这个文件的格式是 USERNAME:UID:RANGE中/etc/passwd或输出中列出的用户名getpwent。
-
为用户分配的初始 UID。 -
为用户分配的 UID 范围的大小。
该usermod程序可用于为用户分配 UID 和 GID,而不是直接更新文件。
[root@localhost ~]# usermod --add-subuids 200000-201000 --add-subgids 200000-201000 hh
grep hh /etc/subuid /etc/subgid
/etc/subuid:hh:200000:1001
/etc/subgid:hh:200000:1001
用户配置文件
三个主要的配置文件是container.conf 、storage.conf 和r egistries.conf 。用户可以根据需要修改这些文件。
container.conf
// 用户配置文件
[root@localhost ~]# cat /usr/share/containers/containers.conf
[root@localhost ~]# cat /etc/containers/containers.conf
[root@localhost ~]# cat ~/.config/containers/containers.conf //优先级最高
如果它们以该顺序存在。每个文件都可以覆盖特定字段的前一个文件。
配置storage.conf文件
1./etc/containers/storage.conf
2.$HOME/.config/containers/storage.conf
在普通用户中**/etc/containers/storage.conf** 的一些字段将被忽略
[root@localhost ~]# vi /etc/containers/storage.conf
[storage]
> 推荐下自己做的 Spring Cloud 的实战项目:
>
>
# Default Storage Driver, Must be set for proper operation.
driver = "overlay" #此处改为overlay
.......
mount_program = "/usr/bin/fuse-overlayfs" #取消注释
[root@localhost ~]# sysctl user.max_user_namespaces=15000 #如果版本为8以下,则需要做以下操作:
在普通用户中这些字段默认
graphroot="$HOME/.local/share/containers/storage"
runroot="$XDG_RUNTIME_DIR/containers"
registries.conf
配置按此顺序读入,这些文件不是默认创建的,可以从/usr/share/containers 或复制文件/etc/containers并进行修改。
1./etc/containers/registries.conf
2./etc/containers/registries.d/*
3.HOME/.config/containers/registries.conf
授权文件
此文件里面写了docker账号的密码,以加密方式显示
[root@localhost ~]# podman login
Username: 1314444
Password:
Login Succeeded!
[root@localhost ~]# cat /run/user/0/containers/auth.json
{
"auths": {
"registry.fedoraproject.org": {
"auth": "MTMxNDQ0NDpIMjAxNy0xOA=="
}
}
}
普通用户是无法看见root用户的镜像的
//root用户
[root@localhost ~]# podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/library/httpd latest ea28e1b82f31 11 days ago 146 MB
//普通用户
[root@localhost ~]# su - zz
[zz@localhost ~]$ podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
卷
-
容器与root用户一起运行,则root容器中的用户实际上就是主机上的用户。 -
UID GID是在/etc/subuid和/etc/subgid等中用户映射中指定的第一个UID GID。 -
如果普通用户的身份从主机目录挂载到容器中,并在该目录中以根用户身份创建文件,则会看到它实际上是你的用户在主机上拥有的。
使用卷
[root@localhost ~]# su - zz
[zz@localhost ~]$ pwd
/home/zz
[zz@localhost ~]$ mkdir /home/zz/data
[zz@localhost ~]$ podman run -it -v "$(pwd)"/data:/data docker.io/library/busybox /bin/sh
Trying to pull docker.io/library/busybox:latest...
Getting image source signatures
Copying blob 3cb635b06aa2 done
Copying config ffe9d497c3 done
Writing manifest to image destination
Storing signatures
/ # ls
bin data dev etc home proc root run sys tmp usr var
/ # cd data/
/data # ls
/data # touch 123
/data # ls -l
total 0
-rw-r--r-- 1 root root 0 Dec 13 00:17 123
在主机上查看
[zz@localhost ~]$ ll data/
总用量 0
-rw-r--r-- 1 zz zz 0 12月 13 00:17 123
//写入文件
[zz@localhost ~]$ echo "hell world" >> 123
[zz@localhost ~]$ cat 123
hell world
容器里查看
/data # cat 123
hell world
//我们可以发现在容器里面的文件的属主和属组都属于root,那么如何才能让其属于tom用户呢?下面告诉你答案
/data # ls -l
total 4
-rw-rw-r-- 1 root root 12 Dec 13 00:20 123
//只要在运行容器的时候加上一个--userns=keep-id即可。
[zz@localhost ~]$ podman run -it --name test -v "$(pwd)"/data:/data --userns=keep-id docker.io/library/busybox /bin/sh
~ $ cd data/
/data $ ls -l
total 4
-rw-r--r-- 1 zz zz 11 Dec 13 00:21 123
使用普通用户映射容器端口时会报“ permission denied”的错误
[zz@localhost ~]$ podman run -d -p 80:80 httpd
Error: rootlessport cannot expose privileged port 80, you can add 'net.ipv4.ip_unprivileged_port_start=80' to /etc/sysctl.conf (currently 1024), or choose a larger port number (>= 1024): listen tcp 0.0.0.0:80: bind: permission denied
普通用户可以映射>= 1024的端口
[zz@localhost ~]$ podman run -d -p 1024:80 httpd
58613a6bdc70d4d4f9f624583f795a62a610596d166f0873bdff8fb26aa15092
[zz@localhost ~]$ ss -anlt
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 128 *:1024 *:*
LISTEN 0 128 [::]:22 [::]:*
配置echo ‘net.ipv4.ip_unprivileged_port_start=80’ >> /etc/sysctl.conf后可以映射大于等于80的端口
[root@localhost ~]# echo 'net.ipv4.ip_unprivileged_port_start=80' >> /etc/sysctl.conf
[root@localhost ~]# sysctl -p
net.ipv4.ip_unprivileged_port_start = 80
[zz@localhost ~]$ podman run -d -p 80:80 httpd
1215455a0c300d78e7bf6afaefc9873f818c6b0f26affeee4e2bc17954e72d8e
[zz@localhost ~]$ ss -anlt
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 128 *:1024 *:*
LISTEN 0 128 *:80 *:*
LISTEN 0 128 [::]:22 [::]:*

















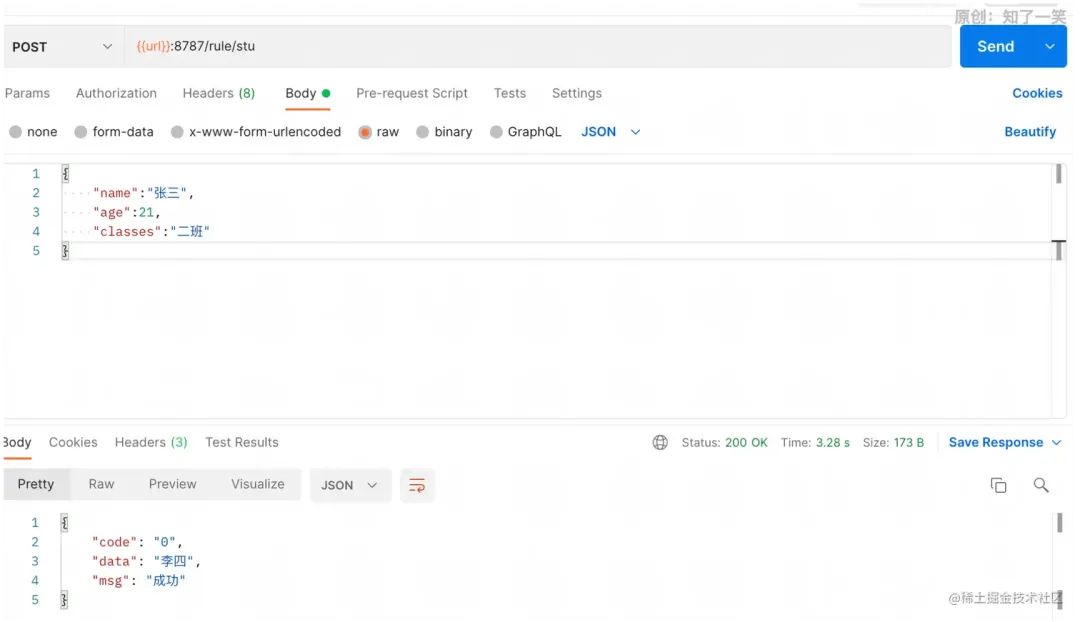 请求接口,最终参数符合配置的条件,返回“那么”中配置的输出结果。
请求接口,最终参数符合配置的条件,返回“那么”中配置的输出结果。