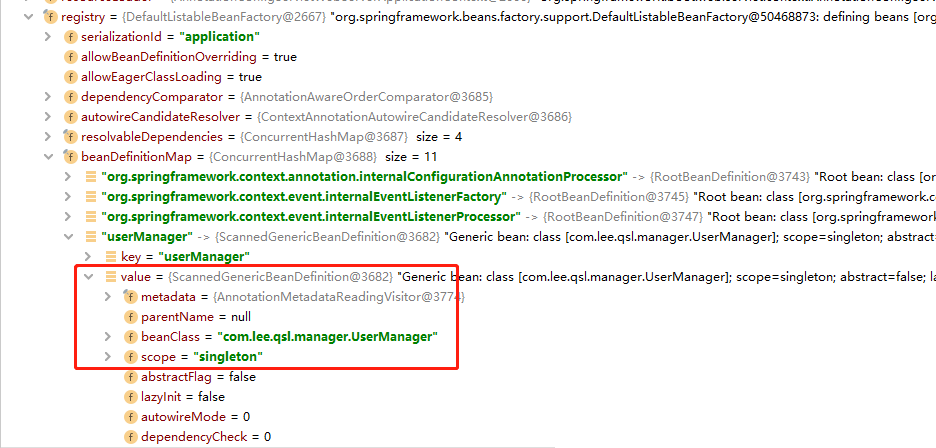
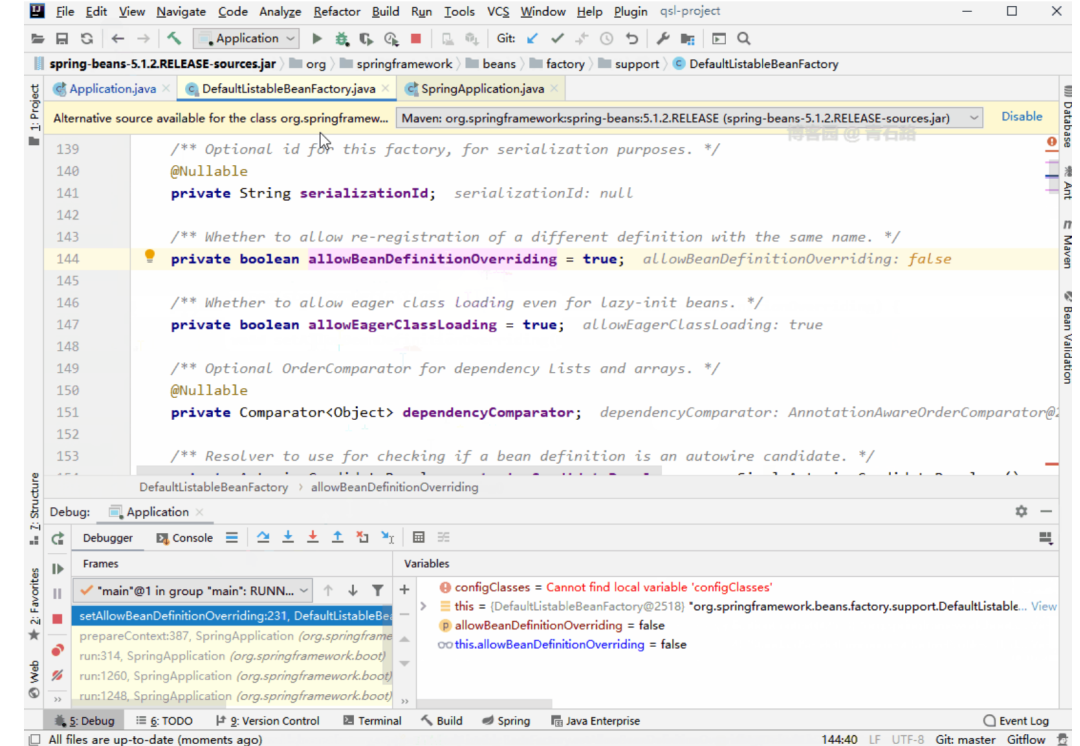
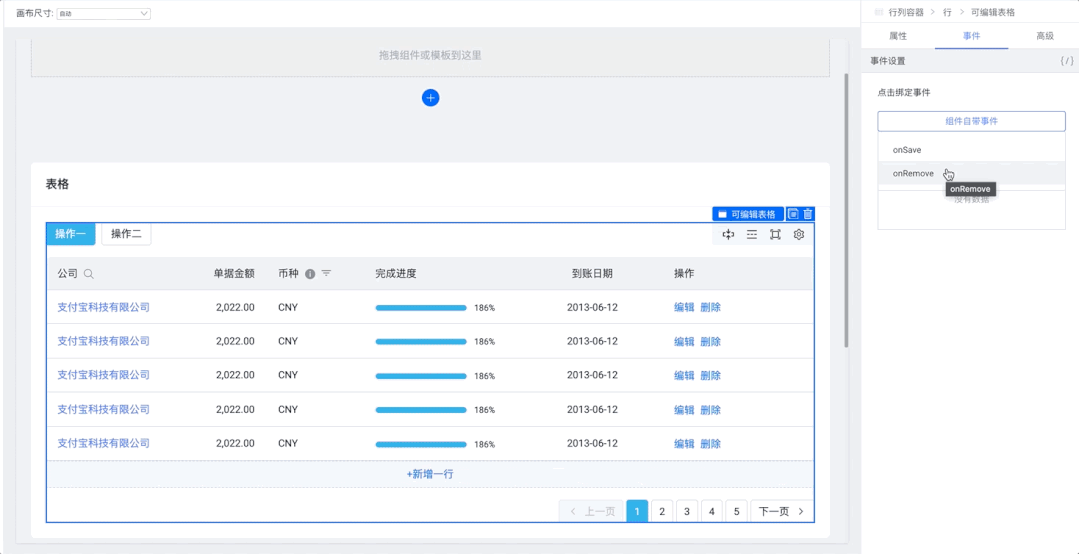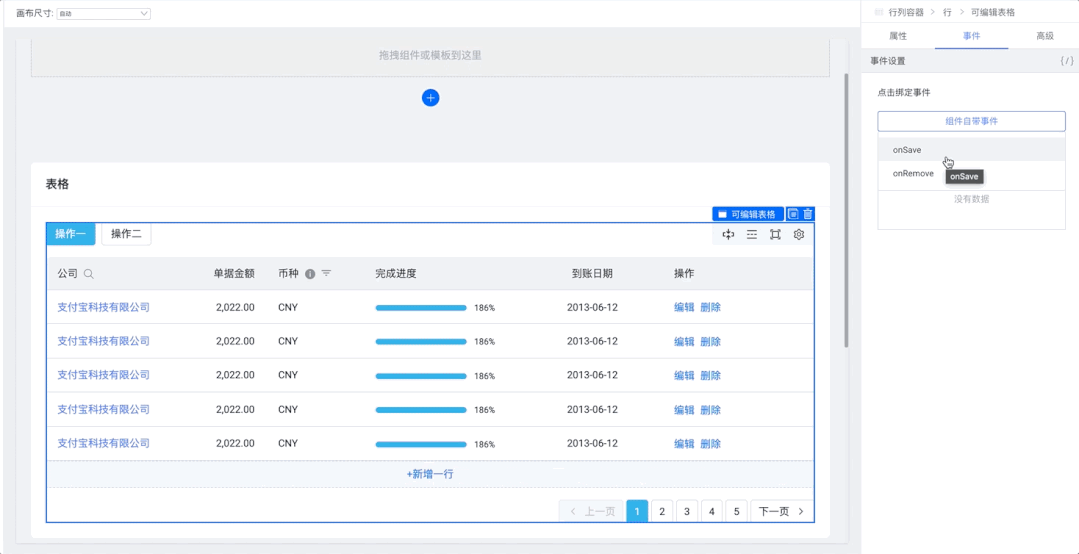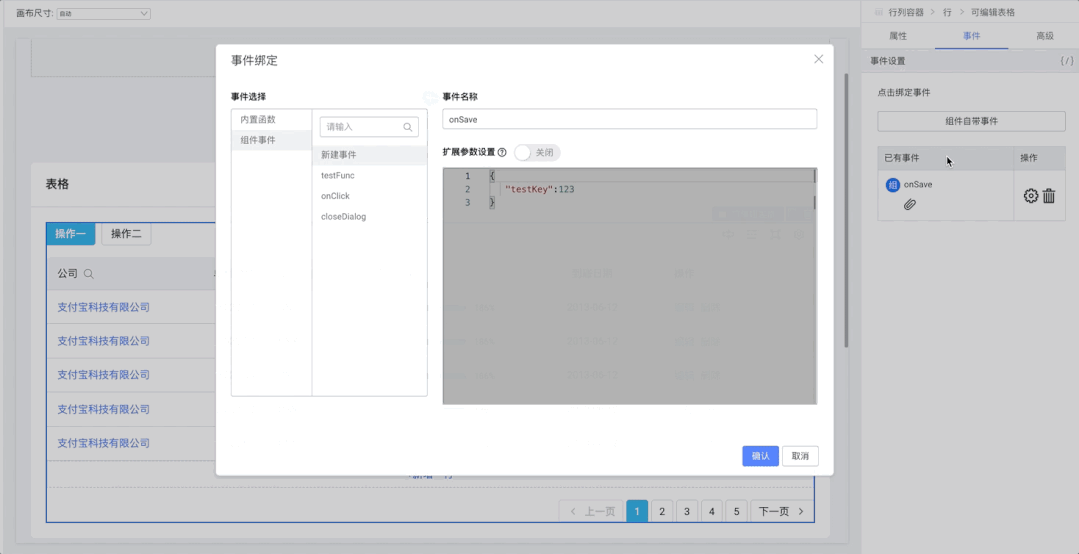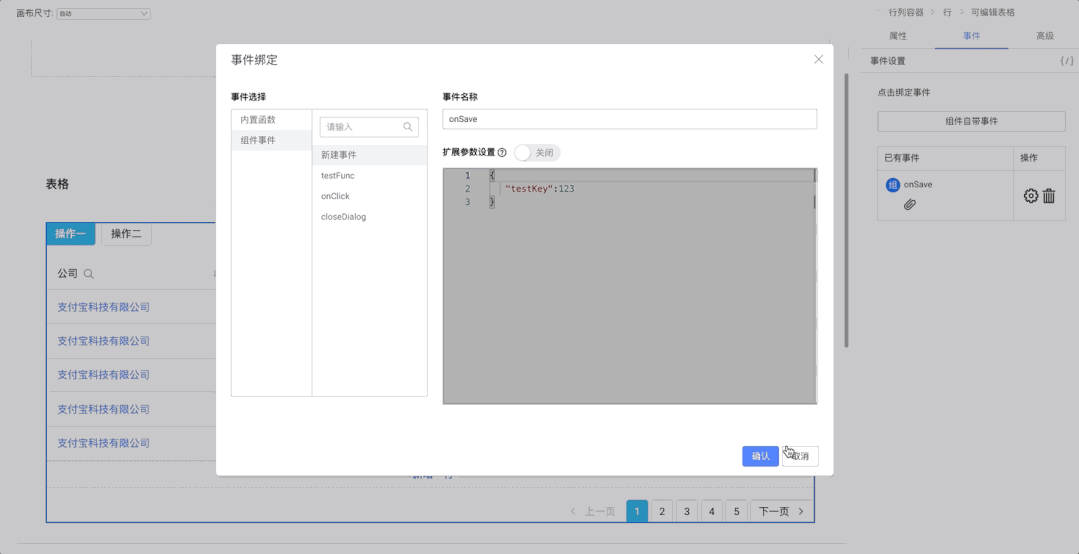
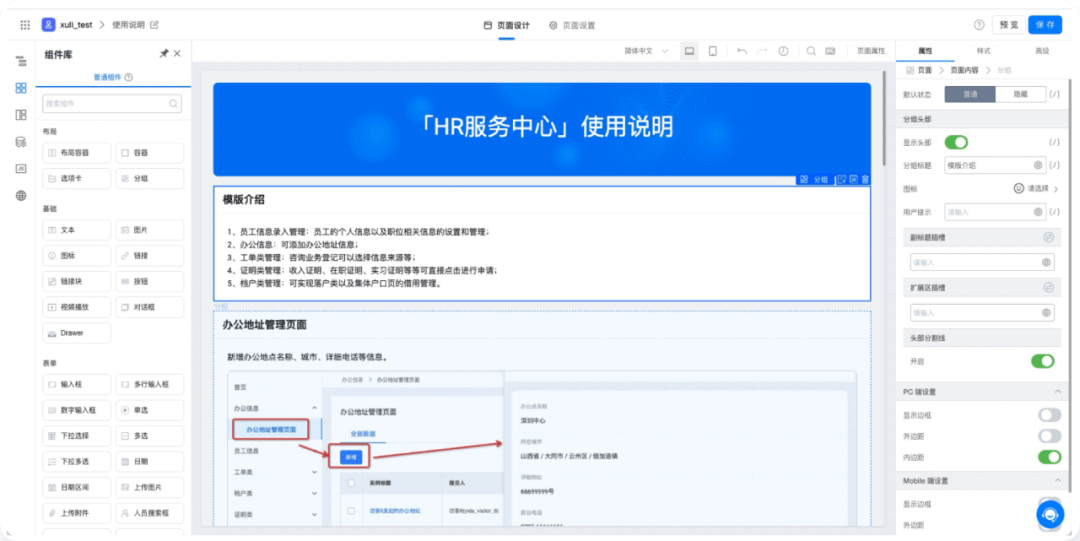
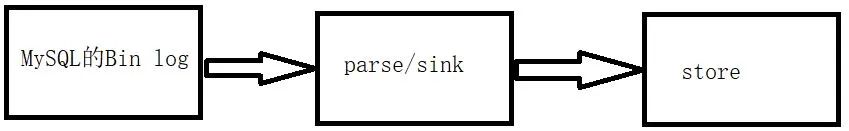2021-10-03 20:37:33.697 INFO 13600 --- [ main] o.s.b.f.s.DefaultListableBeanFactory : Overriding bean definition for bean 'userManager' with a different definition: replacing [Generic bean: class [com.lee.qsl.manager.UserManager]; scope=singleton; abstract=false; lazyInit=false; autowireMode=0; dependencyCheck=0; autowireCandidate=true; primary=false; factoryBeanName=null; factoryMethodName=null; initMethodName=null; destroyMethodName=null; defined in file [D:qsl-projectspring-boot-bean-componenttargetclassescomleeqslmanagerUserManager.class]] with [Root bean: class [null]; scope=; abstract=false; lazyInit=false; autowireMode=3; dependencyCheck=0; autowireCandidate=true; primary=false; factoryBeanName=userConfig; factoryMethodName=userManager; initMethodName=null; destroyMethodName=(inferred); defined in class path resource [com/lee/qsl/config/UserConfig.class]]
只是日志级别是 info ,太不显眼了
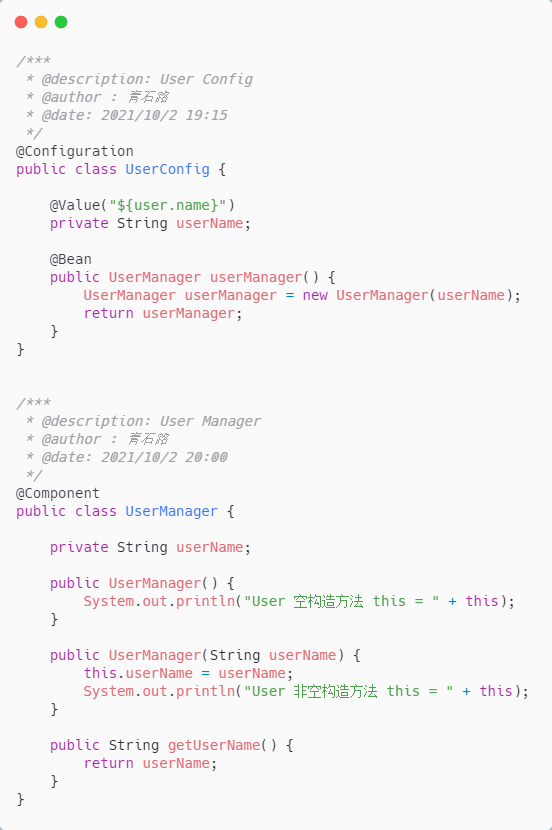
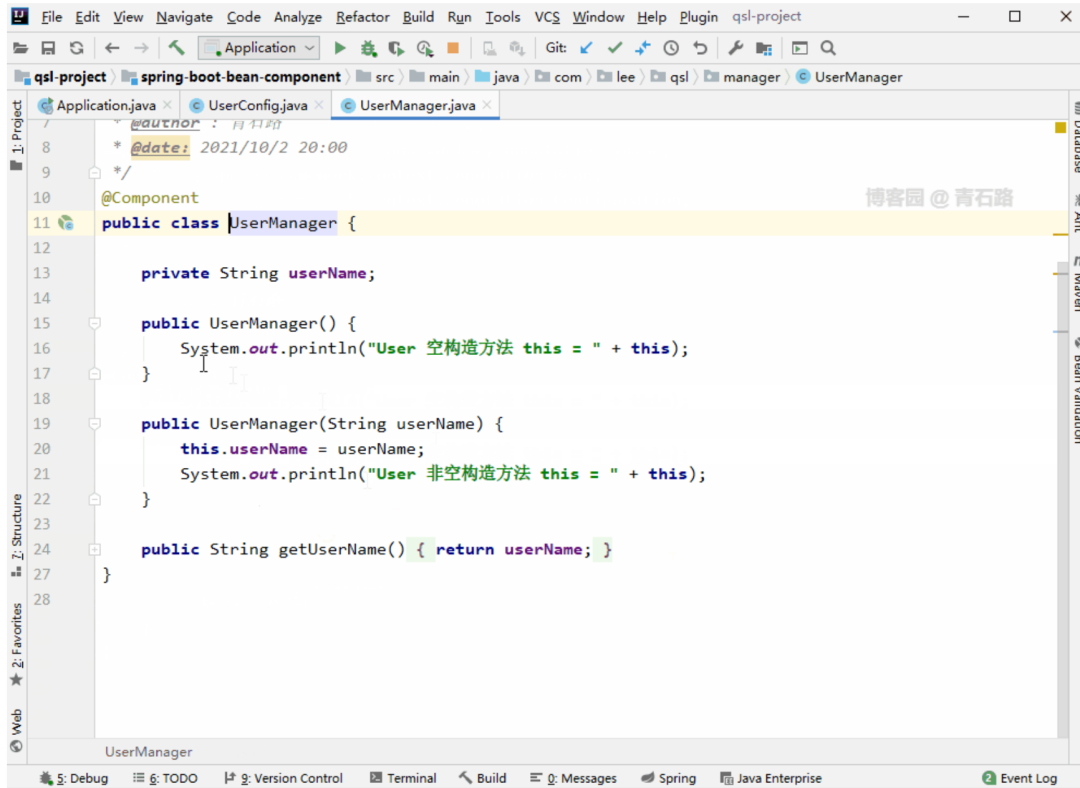
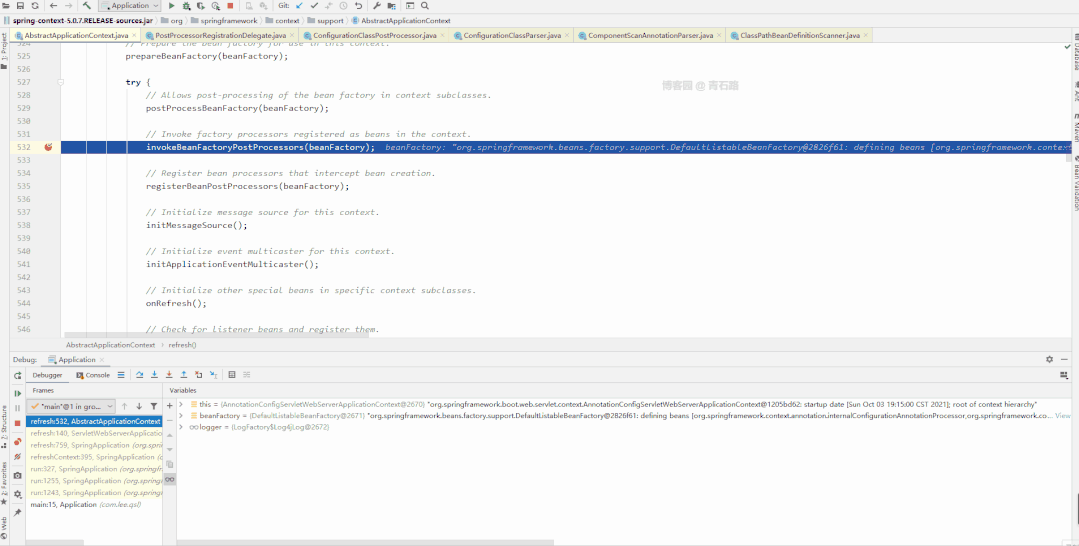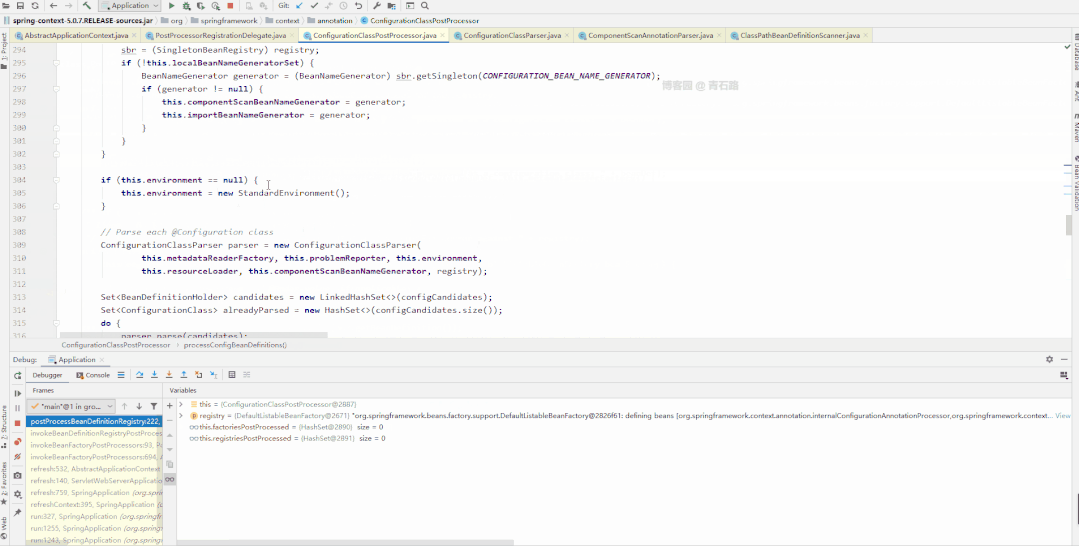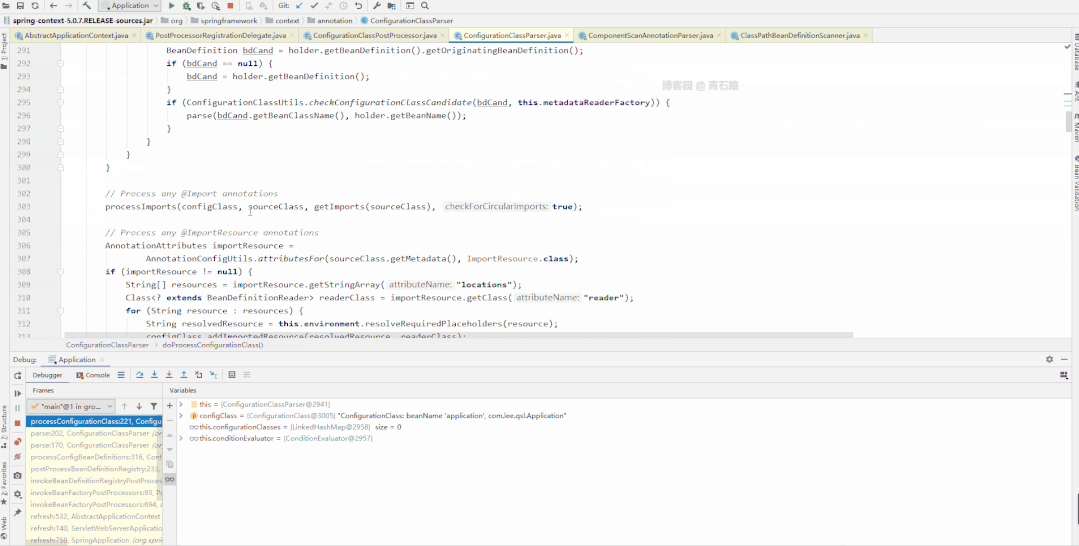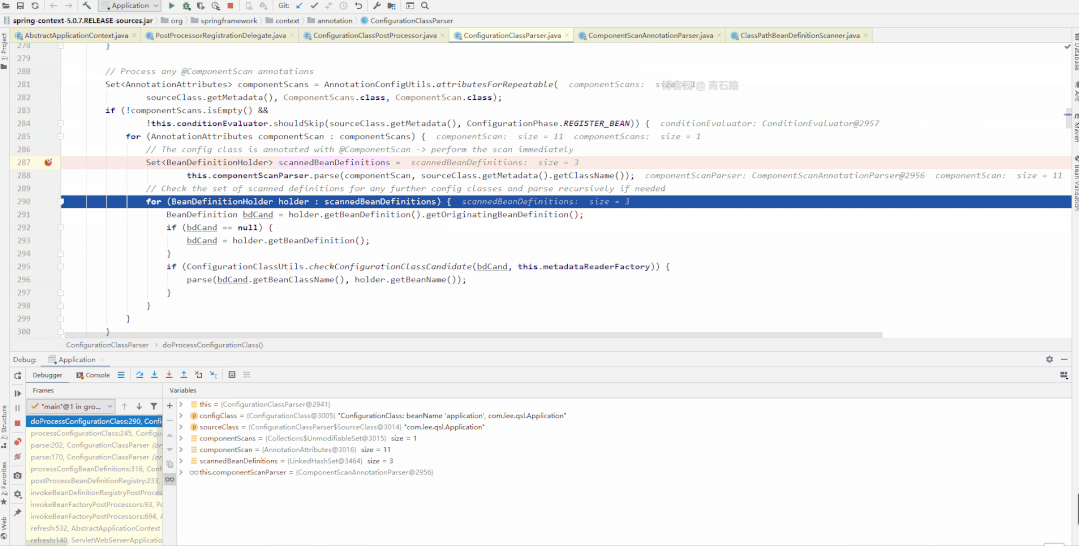
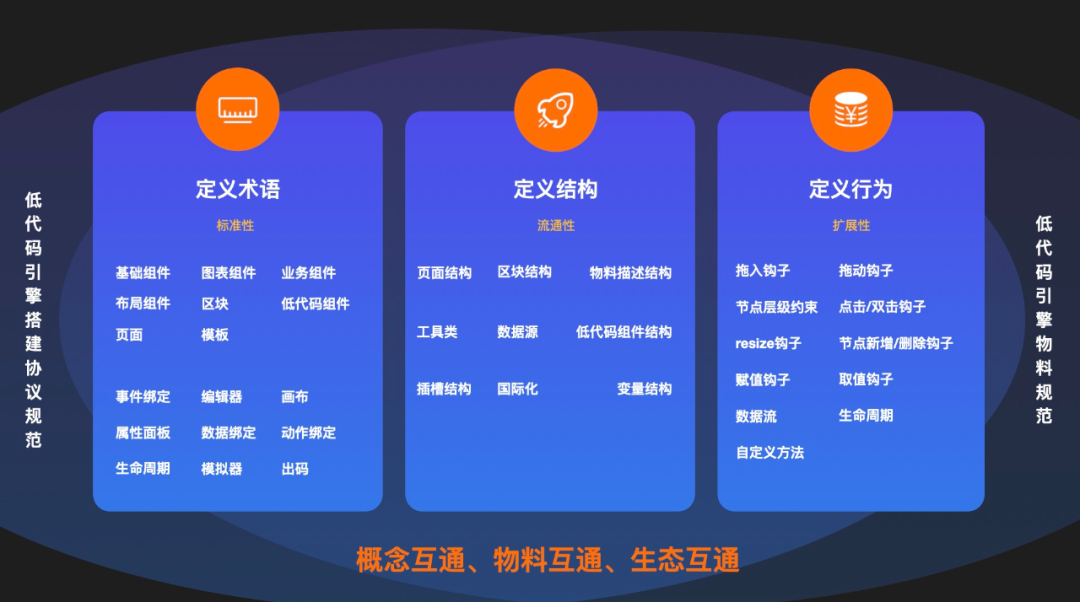
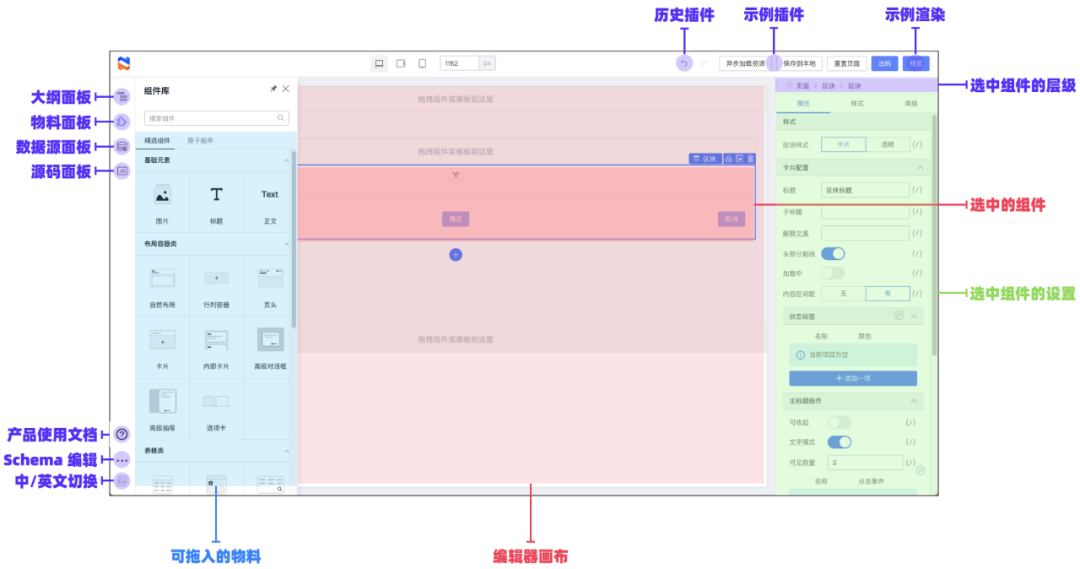
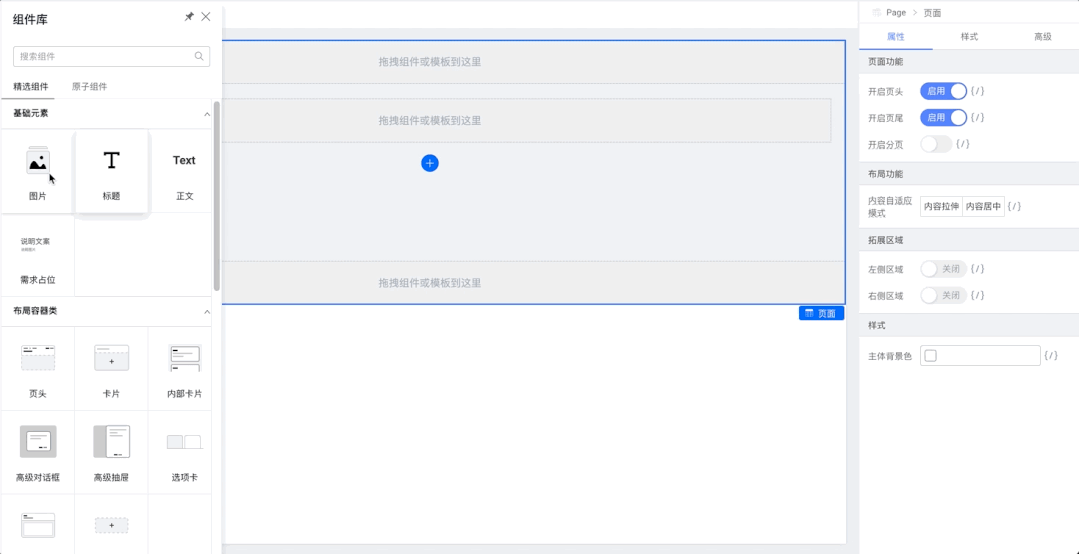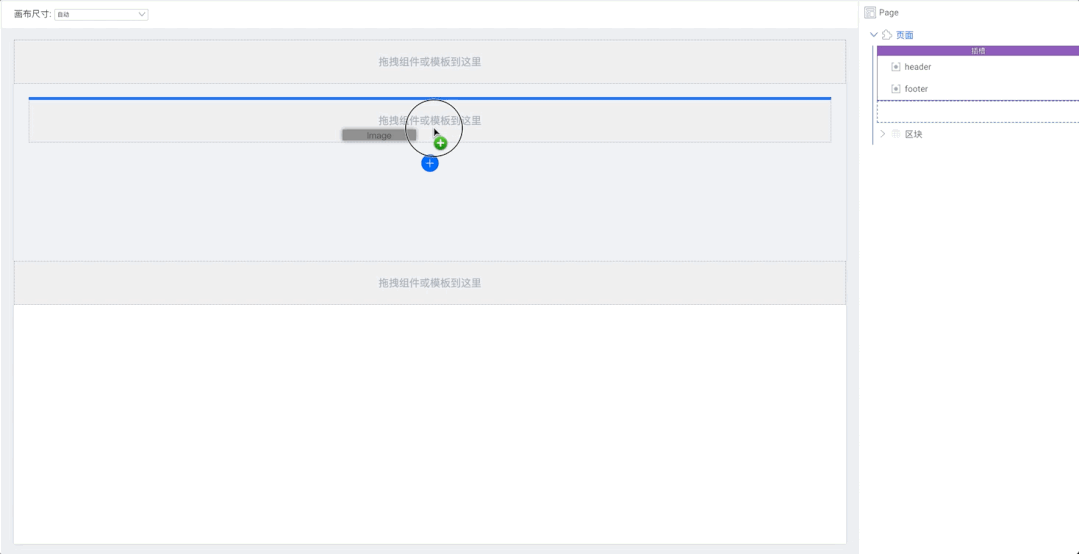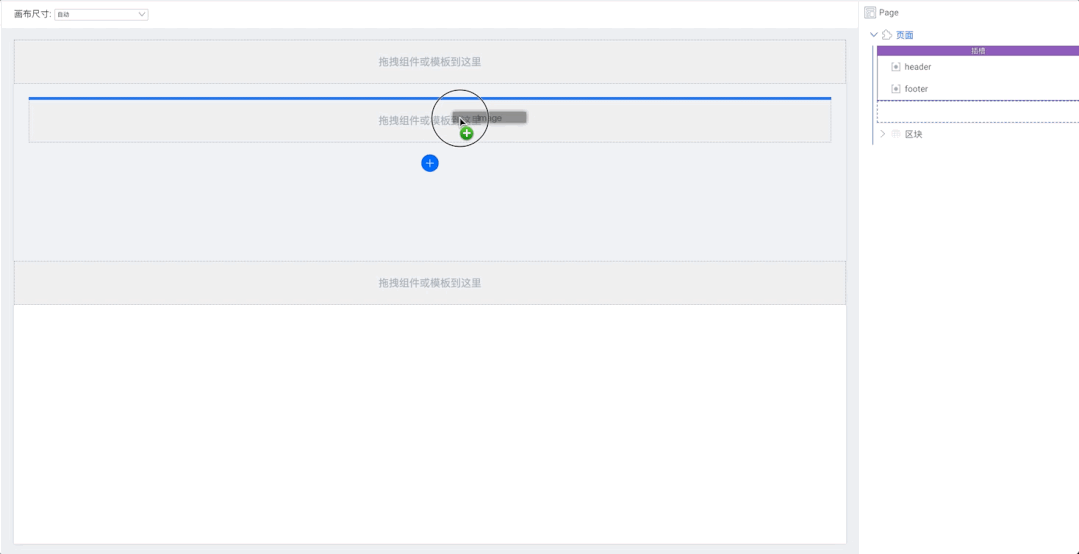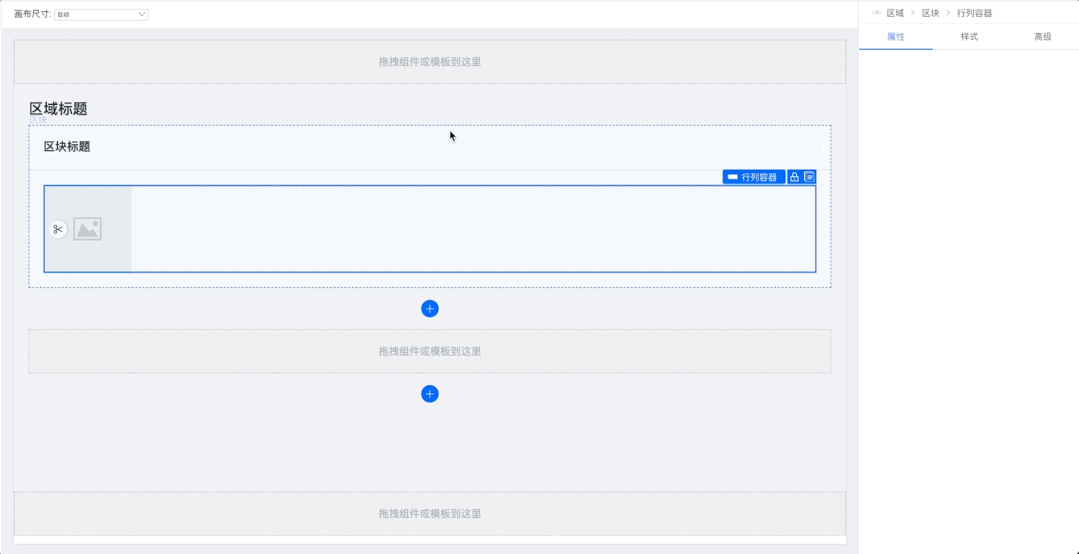
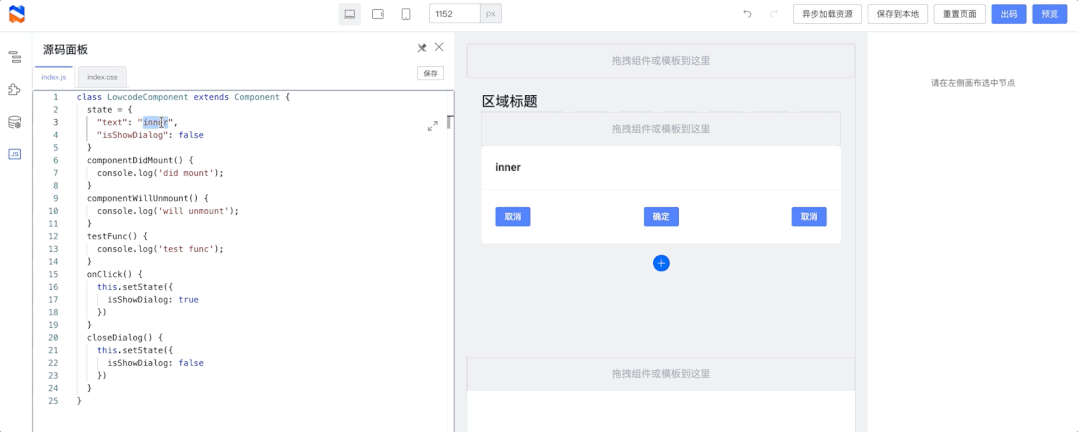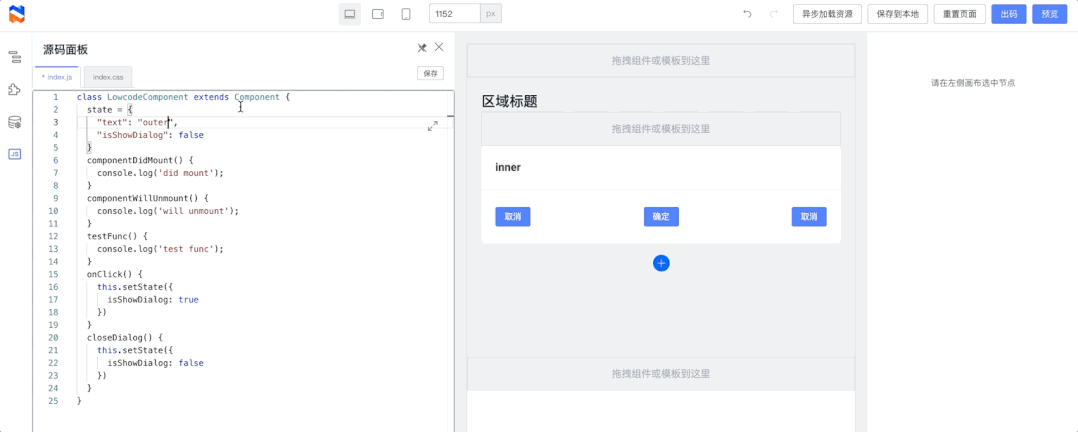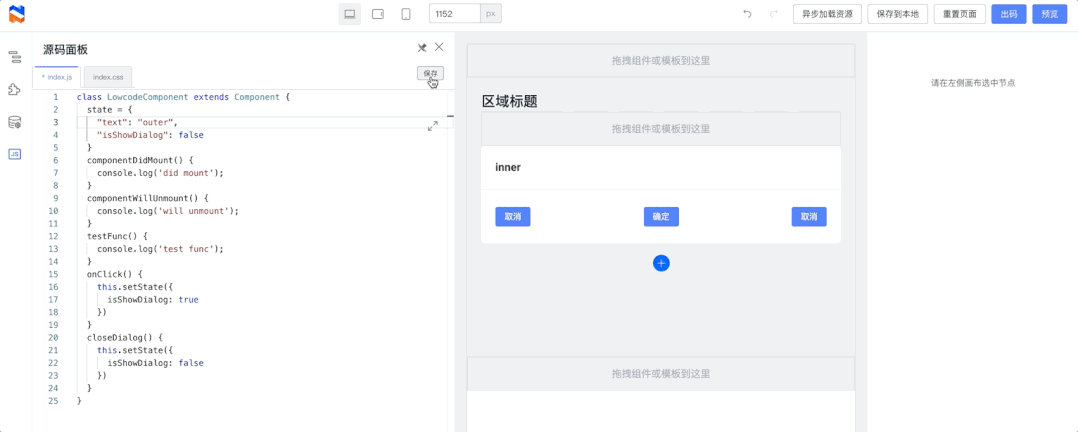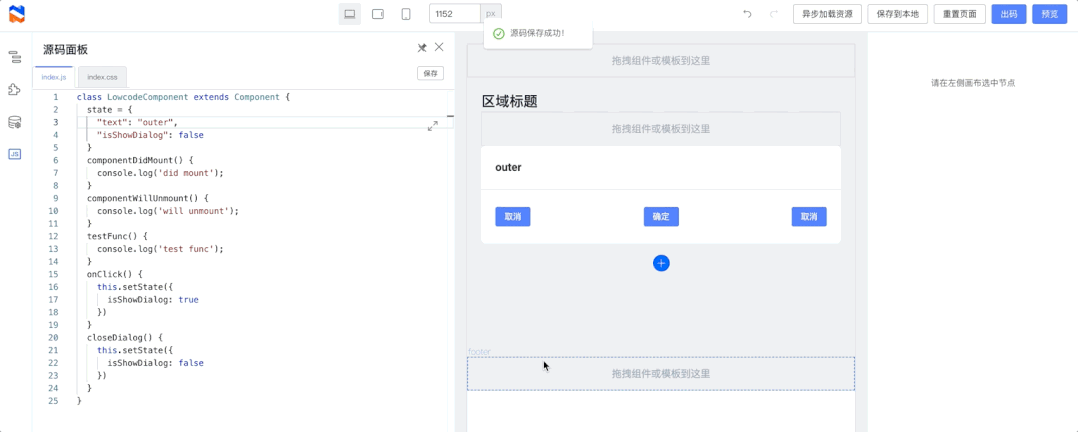
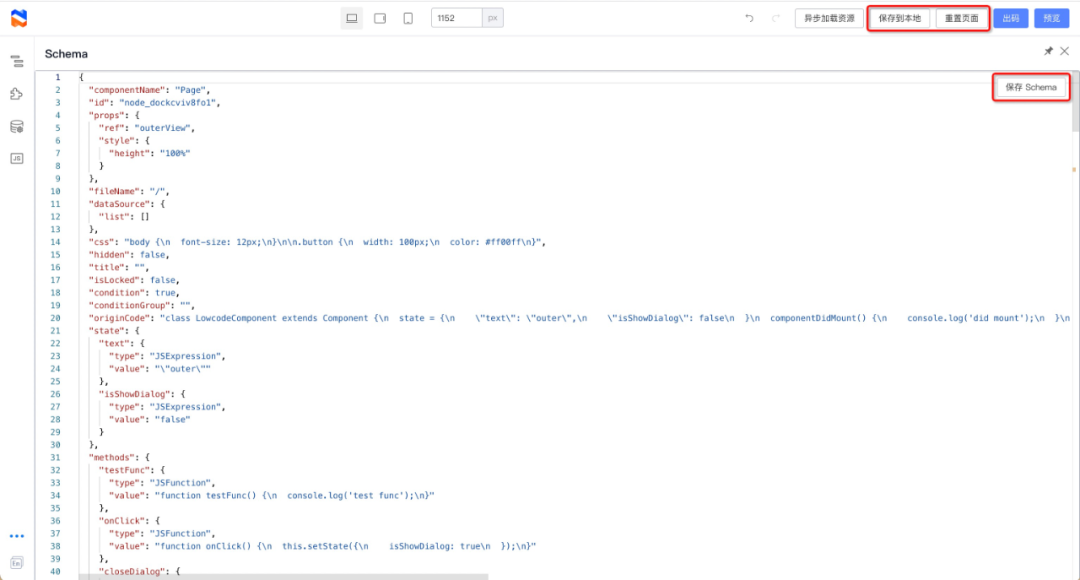
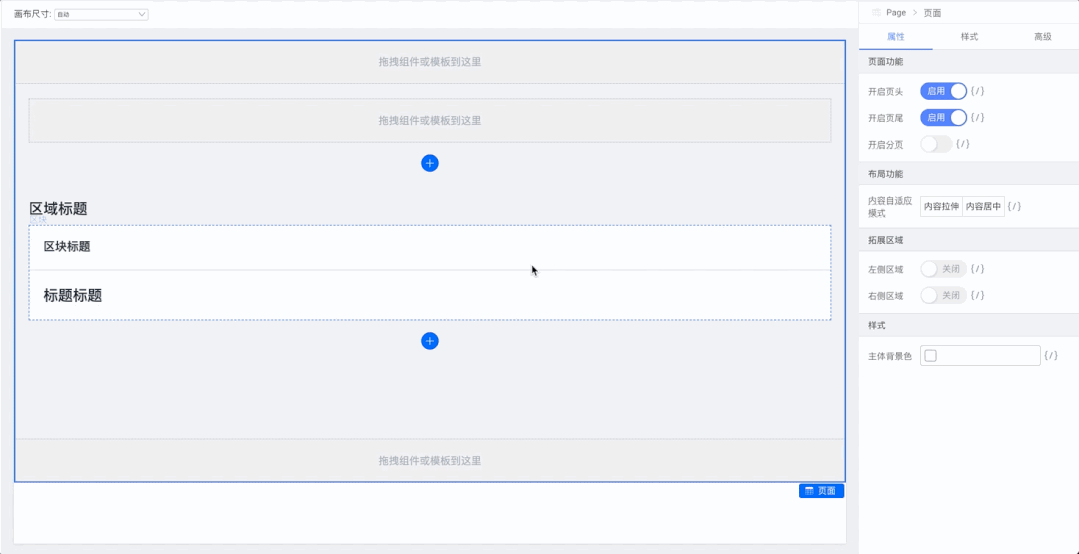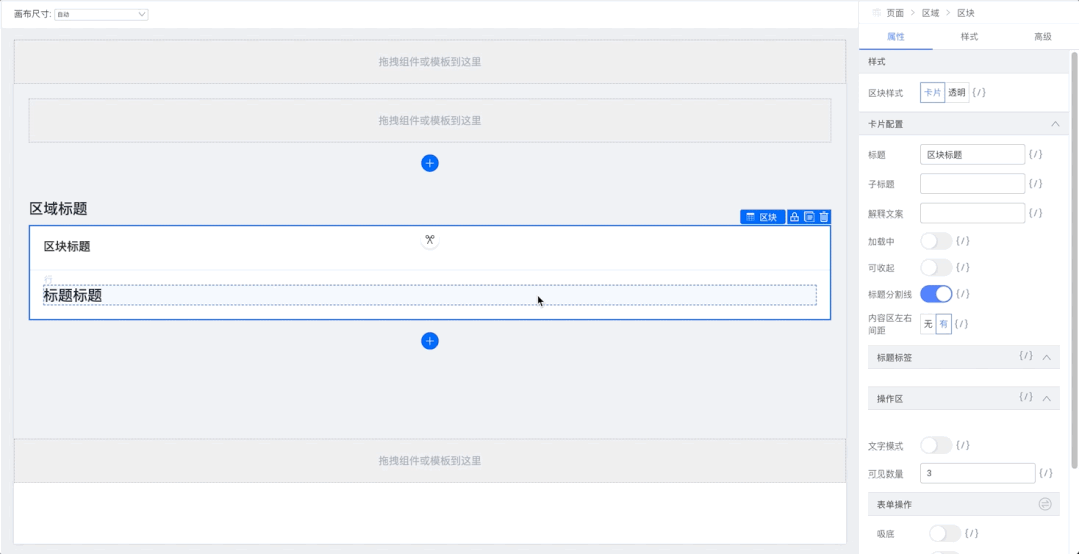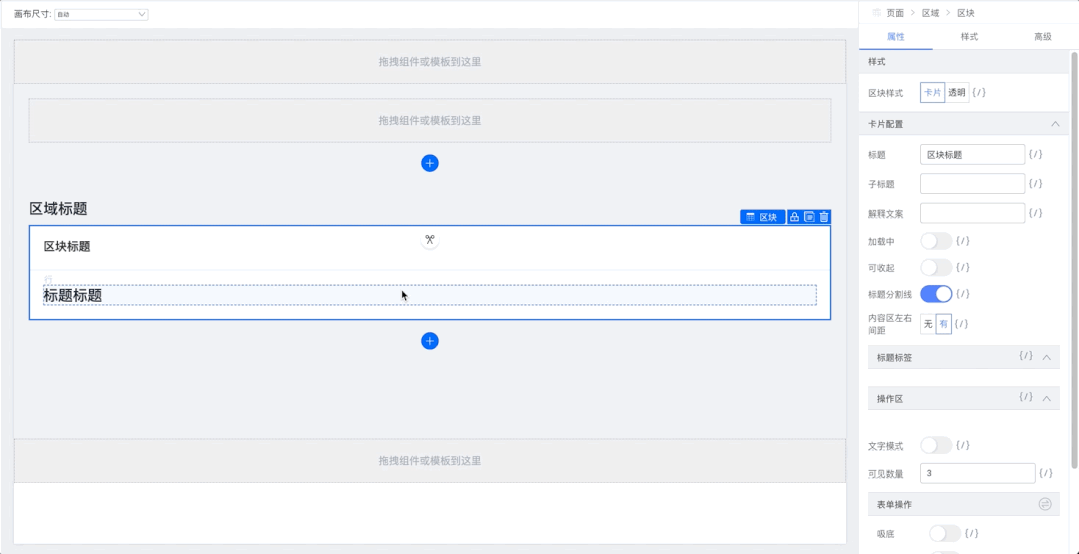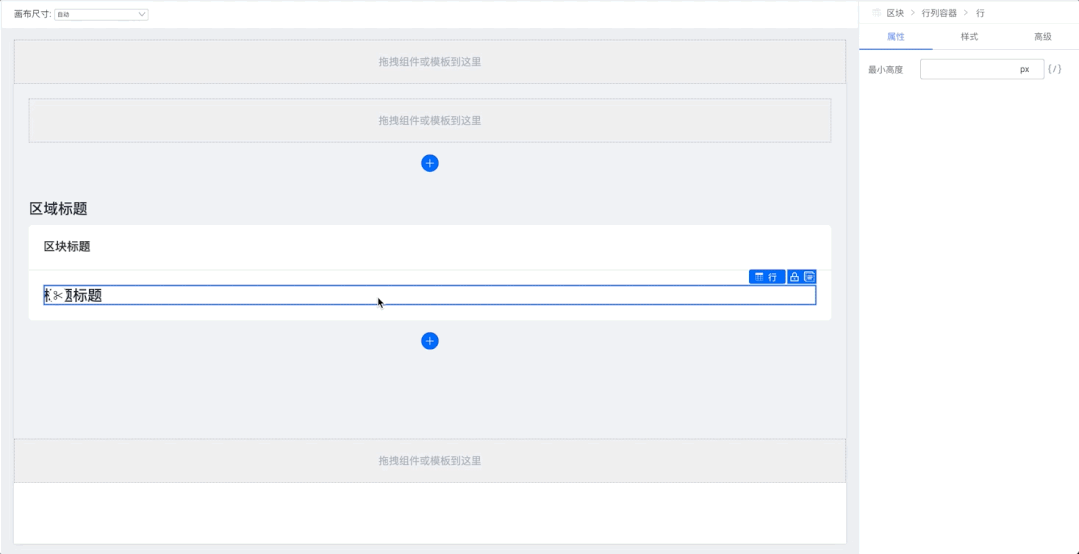
Spring 升级优化
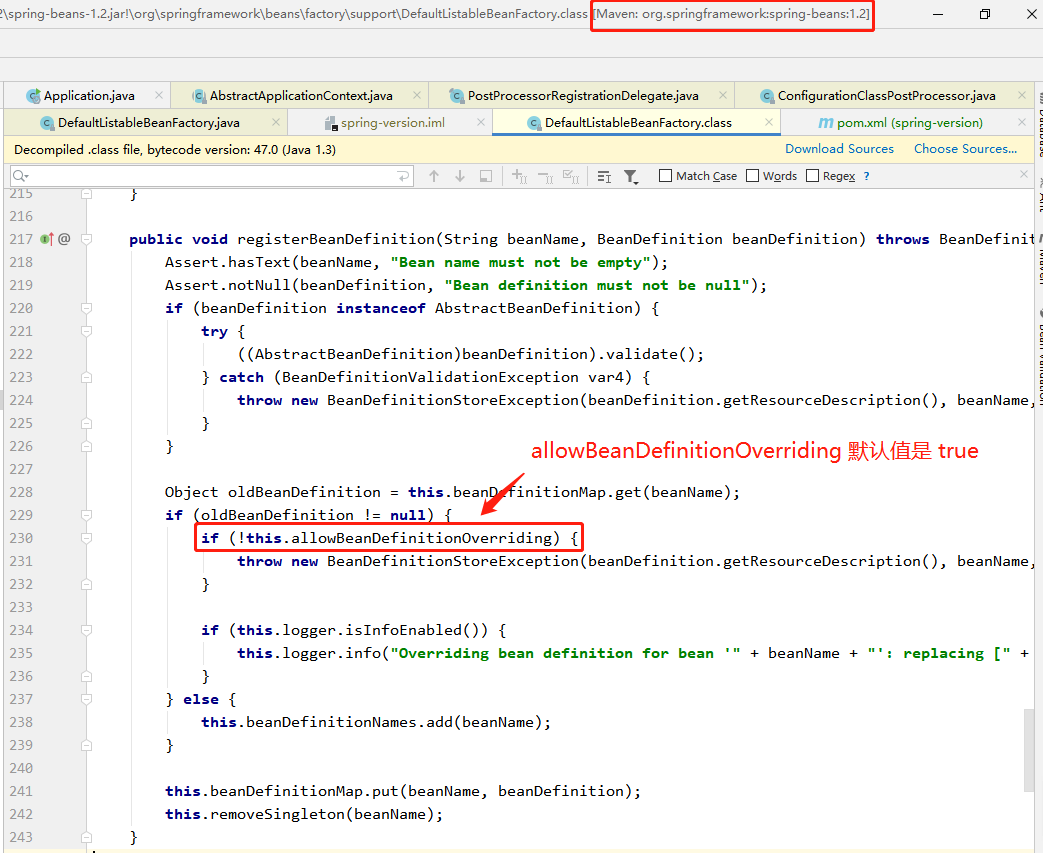
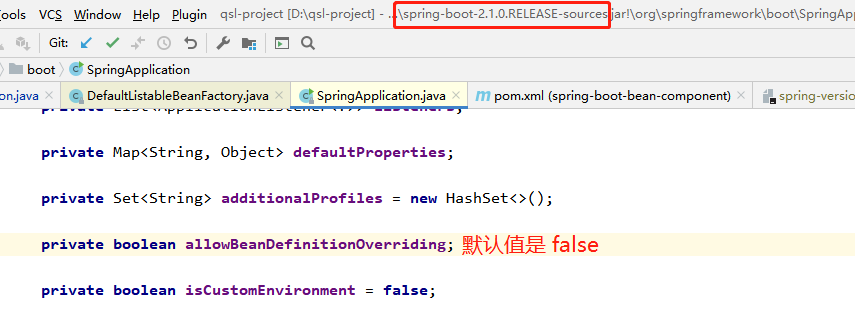
可能 Spring 团队意识到了 info 级别太不显眼的问题,或者说意识到了直接覆盖的处理方式不太合理
所以在 Spring 5.1.2.RELEASE (Spring Boot 则是 2.1.0.RELEASE )做出了优化处理
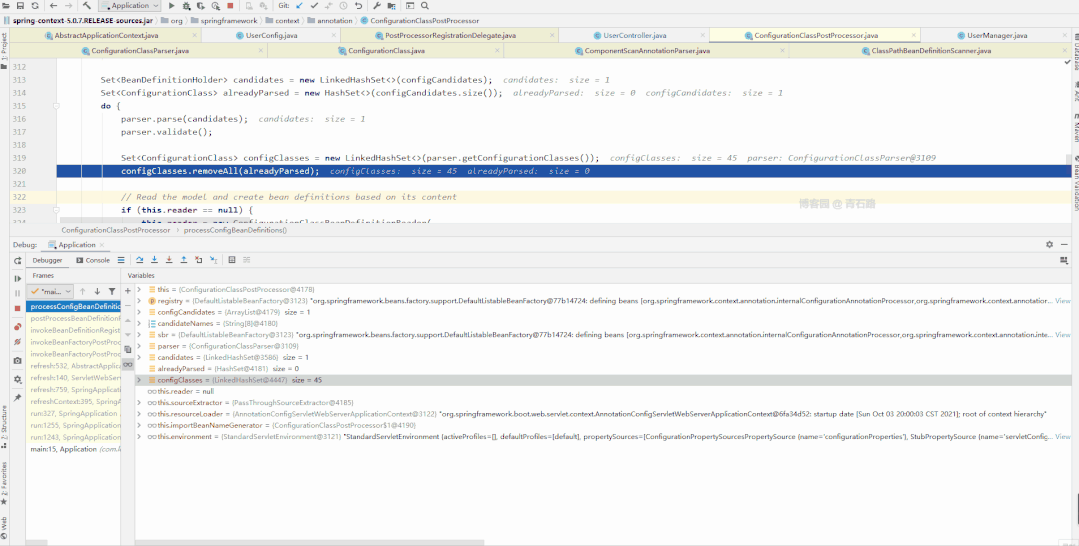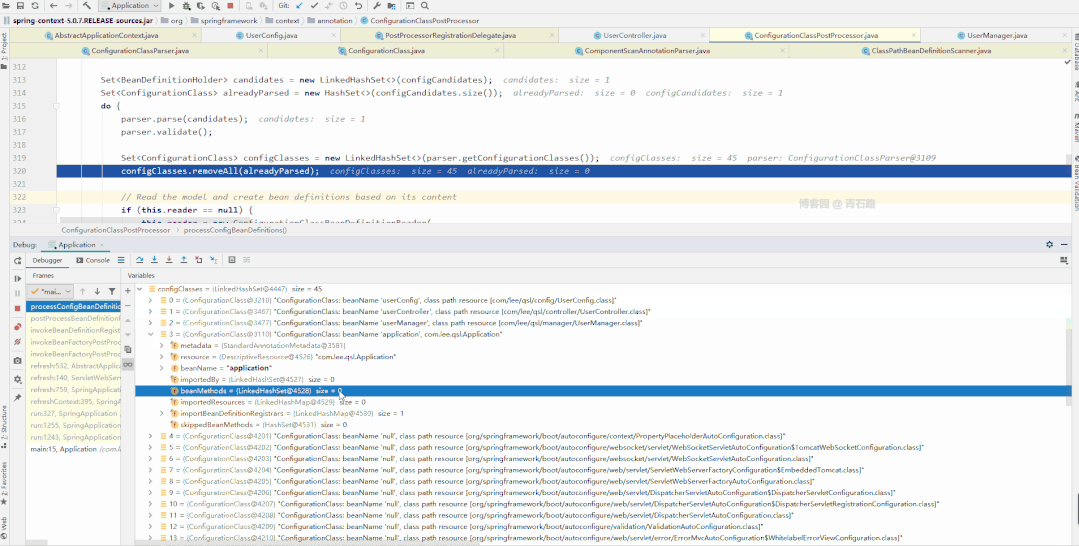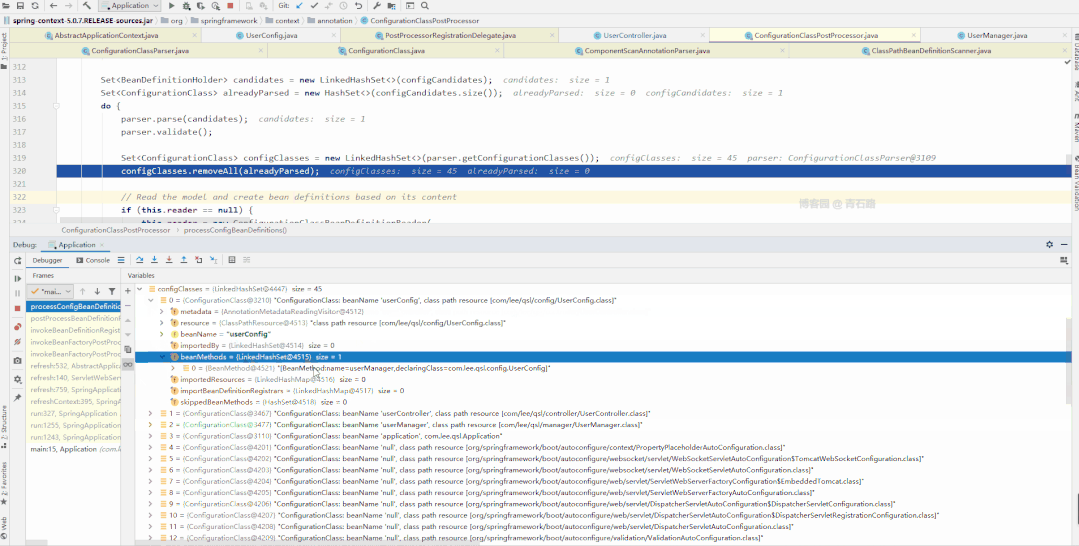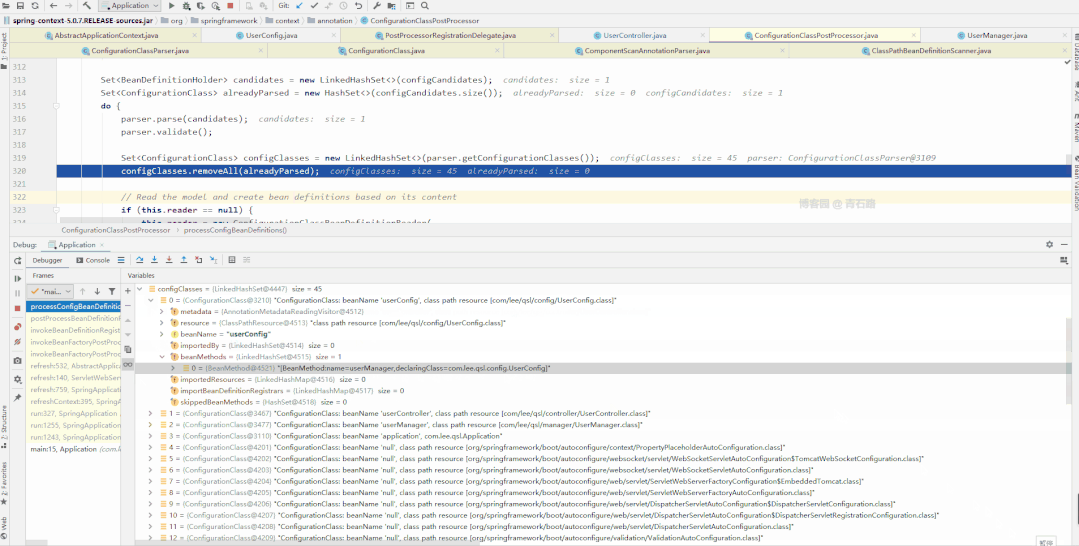
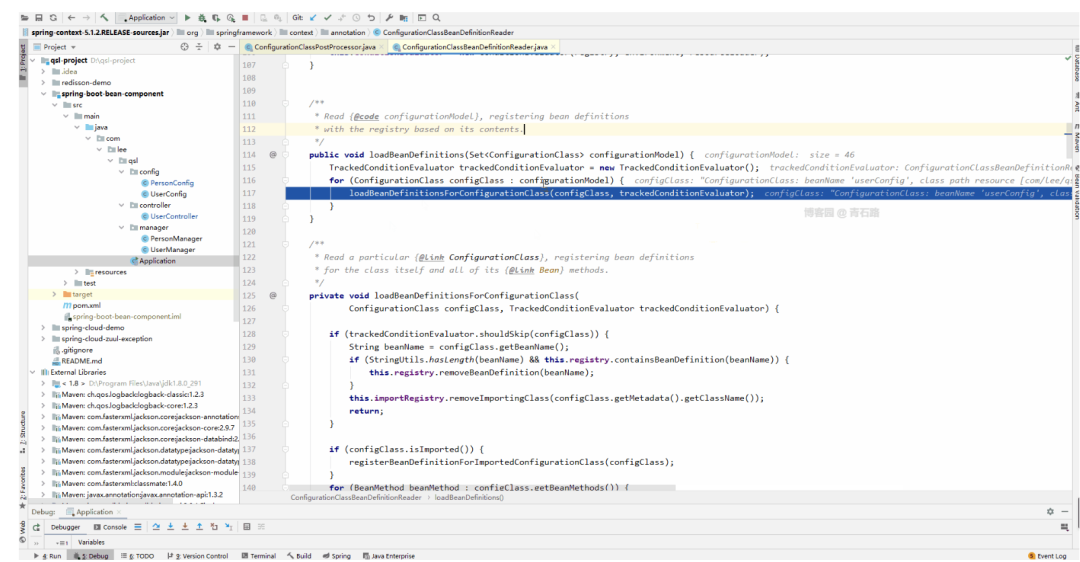
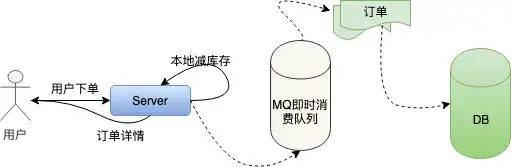
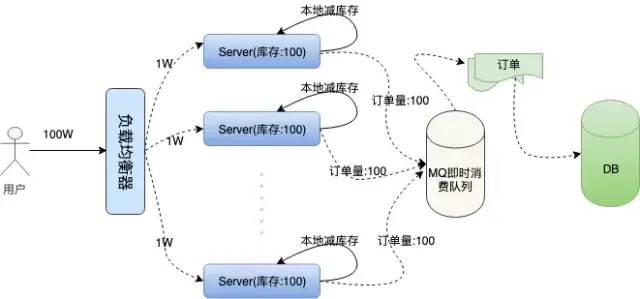
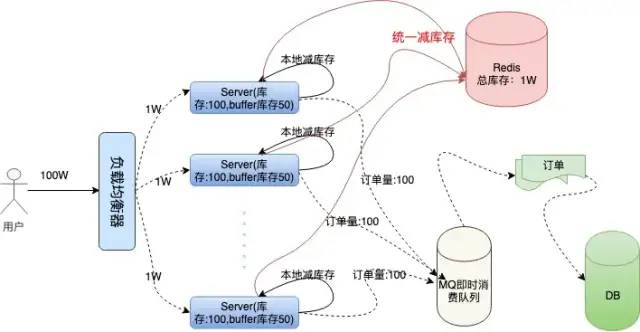
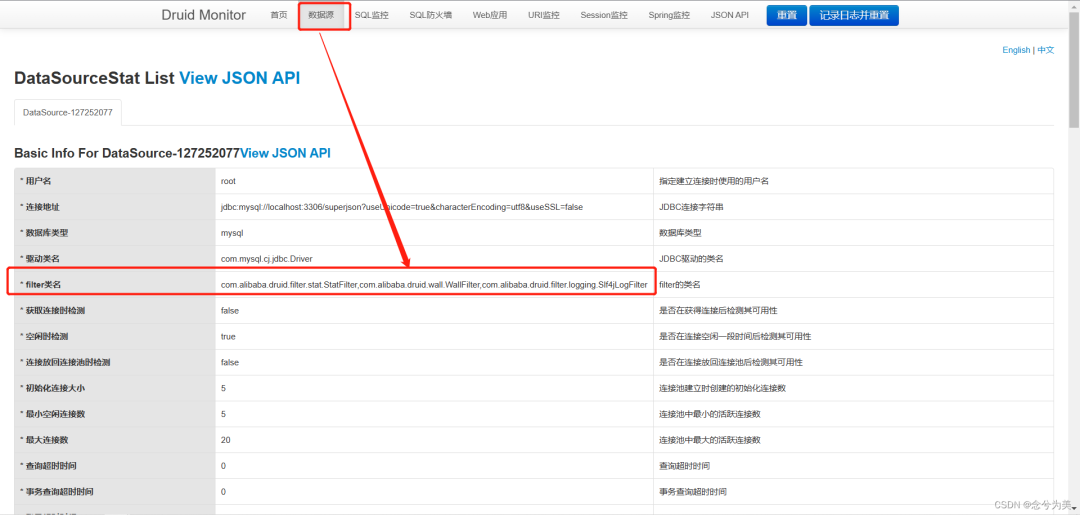
我们来具体看看
图片
启动直接报错,Spring 也给出了提示
The bean 'userManager', defined in class path resource [com/lee/qsl/config/UserConfig.class], could not be registered. A bean with that name has already been defined in file [D:qsl-projectspring-boot-bean-componenttargetclassescomleeqslmanagerUserManager.class] and overriding is disabled.
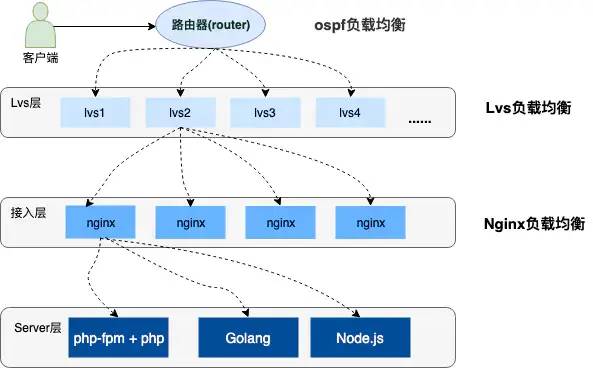
ab -n 10000 -c 100 http://127.0.0.1:3005/buy/ticket
下面是我本地低配mac的压测信息
This is ApacheBench, Version 2.3 1826891 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Concurrency Level: 100 Time taken for tests: 2.339 seconds Complete requests: 10000 Failed requests: 0 Total transferred: 1370000 bytes HTML transferred: 290000 bytes Requests per second: 4275.96 [#/sec] (mean) Time per request: 23.387 [ms] (mean) Time per request: 0.234 [ms] (mean, across all concurrent requests) Transfer rate: 572.08 [Kbytes/sec] received
Connection Times(ms) min mean[+/-sd] median max Connect: 0 8 14.7 6 223 Processing: 2 15 17.6 11 232 Waiting: 1 11 13.5 8 225 Total: 7 23 22.8 18 239
Percentage of the requests served within a certain time(ms) 50% 18 66% 24 75% 26 80% 28 90% 33 95% 39 98% 45 99% 54 100% 239 (longest request)
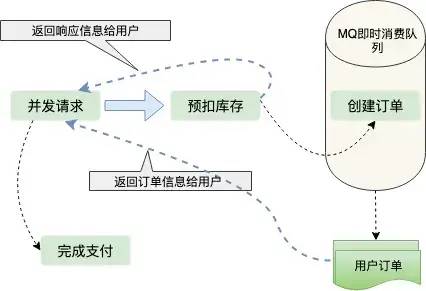
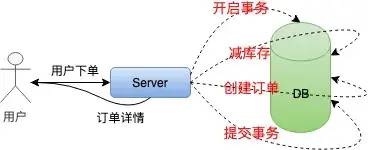
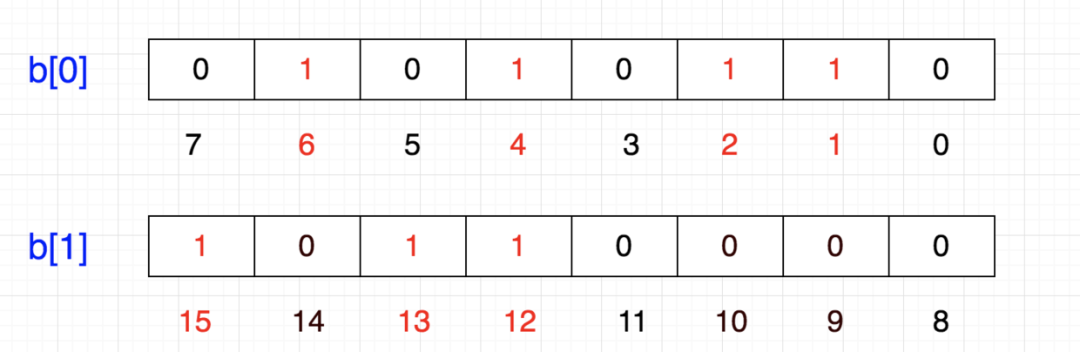
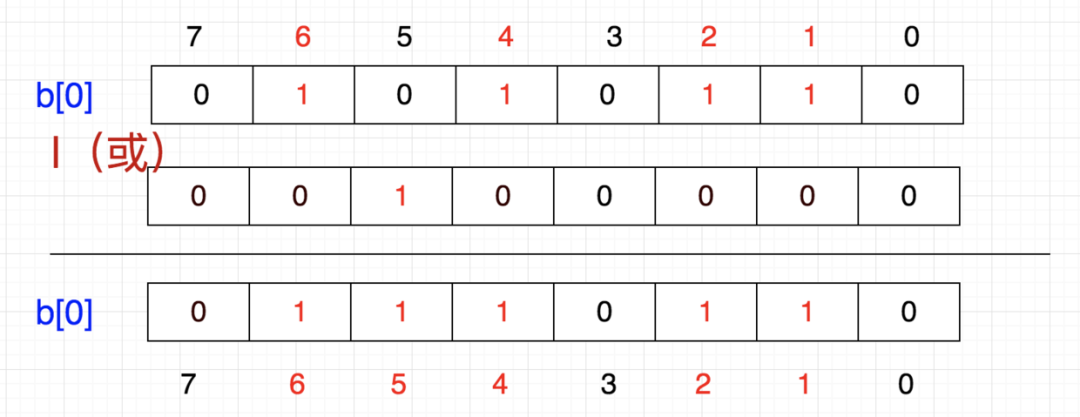
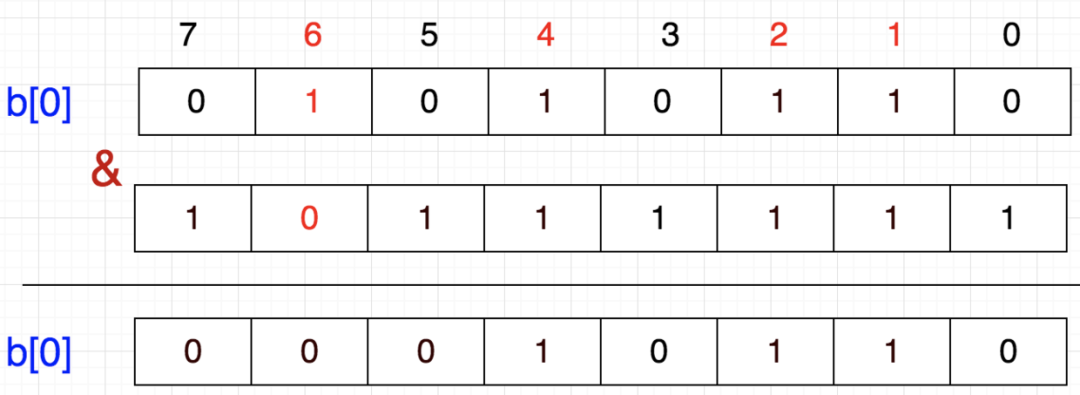
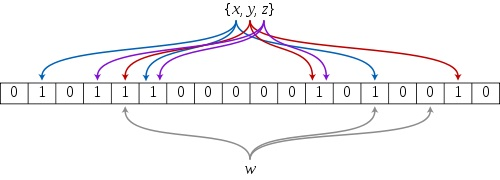
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组(Bit array)中的 K 个点,把它们置为 1 。检索时,只要看看这些点是不是都是1就知道元素是否在集合中;如果这些点有任何一个 0,则被检元素一定不在;如果都是1,则被检元素很可能在(之所以说“可能”是误差的存在)。
BloomFilter 流程
1、 首先需要 k 个 hash 函数,每个函数可以把 key 散列成为 1 个整数;
2、初始化时,需要一个长度为 n 比特的数组,每个比特位初始化为 0;
3、某个 key 加入集合时,用 k 个 hash 函数计算出 k 个散列值,并把数组中对应的比特位置为 1;
4、判断某个 key 是否在集合时,用 k 个 hash 函数计算出 k 个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
 来源:cnblogs.com/youzhibing/p/15354706.html
来源:cnblogs.com/youzhibing/p/15354706.html